


1. Übersicht
In diesem Tutorial lernen wir, wie wir ein vollständiges RAG-Chatbot-System mit Spring AI erstellen, das es uns ermöglicht, mit den Dokumenten zu chatten, die wir hochladen.
Kurz gesagt, wir werden TikaDocumentReader verwenden, um das Dokument zu parsen, die Abschnitte an OpenAI zu senden und die Embeddings zu erstellen. Dann werden diese Embeddings in einer Postgres-Datenbank mit PGvector gespeichert, und wir können die Datenbank abfragen, um die Embeddings zu erhalten, die der Benutzeranfrage am ähnlichsten sind. Sobald wir diese Informationen haben, können wir ein Gespräch mit unserem Chatbot beginnen und die relevantesten Informationen aus dem Dokument erhalten.
Lassen Sie uns mit der Erstellung eines neuen Spring AI-Projekts mit Vaadin beginnen.
2. Erforderliche Abhängigkeiten
Wir werden den Spring Initializr verwenden, um ein neues Projekt mit den folgenden Abhängigkeiten zu erstellen:
- Vaadin
- OpenAI
- Tika Document Reader
- PGvector Vector Database
- Docker Compose Support (optional)
Um korrekt zu laufen, wird die Anwendung in diesem Tutorial Docker verwenden, um eine Instanz von Postgres zu erstellen, die mit PGvector-Erweiterungen konfiguriert ist. Alternativ können wir eine Postgres-Instanz unserer Wahl verwenden und die PGvector-Erweiterung manuell installieren.
3. Konfigurieren der Anwendungs-Eigenschaften
Bevor wir mit dem Schreiben der Geschäftslogik beginnen, müssen wir die Anwendung konfigurieren, damit wir den richtigen OpenAI API-Schlüssel und die Modelle auswählen können:
spring.ai.openai.api-key=YOUR_OPENAI_API_KEY
spring.ai.openai.chat.options.model=gpt-4o-mini
Hier haben wir uns entschieden, das Modell gpt-4o-mini zu verwenden, aber wir können es durch jedes andere verfügbare Modell bei OpenAI ersetzen. Als Nächstes konfigurieren wir unseren Vektor-Store:
spring.ai.vectorstore.pgvector.initialize-schema=true
spring.ai.vectorstore.pgvector.index-type=HNSW
spring.ai.vectorstore.pgvector.distance-type=COSINE_DISTANCE
spring.ai.vectorstore.pgvector.dimensions=1536
Hier haben wir uns entschieden, den HNSW-Indextyp und COSINE_DISTANCE als Distanztyp zu verwenden. Wir setzen die Dimensionen auf 1536, da dies die Dimension der von OpenAI generierten Embeddings ist.
Als Nächstes konfigurieren wir eine docker-compose-Datei, um eine Postgres-Instanz mit PGvector-Erweiterungen zu starten:
services:
pgvector:
image: 'pgvector/pgvector:pg16'
environment:
- 'POSTGRES_DB=mydatabase'
- 'POSTGRES_PASSWORD=secret'
- 'POSTGRES_USER=myuser'
labels:
- "org.springframework.boot.service-connection=postgres"
ports:
- '5432'
Diese Datei ist eine einfache docker-compose-Datei, die eine Postgres-Instanz mit dem pgvector/pgvector:pg16 Image startet und den Port 5432 für den Host-Rechner freigibt. Wir haben uns entschieden, dieses Image zu verwenden, da die pgvector-Erweiterung bereits installiert und konfiguriert ist. Außerdem werden wir der Anwendung mitteilen, die Datenbank zu stoppen, wenn die Anwendung stoppt:
spring.docker.compose.stop.command=stop
Nachdem wir die Unterstützung für Docker Compose hinzugefügt haben, wird unsere Anwendung die Erstellung der Datenbank mithilfe dieser Konfigurationsdatei übernehmen und die korrekten Eigenschaften zur Verbindung mit der Datenbank einfügen. Wenn wir uns entscheiden, eine andere Datenbank zu verwenden, können wir die Verbindungseigenschaften in der application.properties-Datei wie bei einer üblichen Spring Data JPA-Anwendung konfigurieren:
spring.datasource.url=jdbc:postgresql://localhost:5432/mydatabase
spring.datasource.username=myuser
spring.datasource.password=secret
spring.datasource.driver-class-name=org.postgresql.Driver
4. Eine Vaadin-Anwendung erstellen
Nun, da unsere Konfiguration abgeschlossen ist, werden wir eine Vaadin-Anwendung erstellen, die es uns ermöglicht, ein Dokument hochzuladen und ein Gespräch mit dem Chatbot zu beginnen.
Lassen Sie uns den Haupteinstiegspunkt unserer Anwendung erstellen:
@SpringBootApplication
public class RagSpringAiApplication implements AppShellConfigurator {
public static void main(String[] args) {
SpringApplication.run(RagSpringAiApplication.class, args);
}
}
Wir verwenden das AppShellConfigurator-Interface, um das Anwendungsshell als die standardmäßige Vaadin-Anwendung zu konfigurieren.
Als nächstes erstellen wir ein einfaches Layout, um zu überprüfen, ob alles funktioniert:
@Route("")
@PageTitle("Chatbot")
public class MainView extends VerticalLayout {
public MainView() {
add(new H1("Hello, World!"));
}
}
Wenn alles korrekt funktioniert, sollten wir eine einfache Seite mit dem Titel Hello, World! sehen:

Da wir nun das Rückgrat einer einfachen Anwendung haben, können wir beginnen, alle benötigten Dienste und Komponenten zu entwickeln.
5. Erstellen Sie eine Upload-Komponente
Das erste, was wir benötigen, ist eine Komponente, die es uns ermöglicht, ein Dokument auf den Server hochzuladen. Dafür verwenden wir die Upload-Komponente von Vaadin und erweitern sie, um unseren Anforderungen gerecht zu werden:
private Upload createUploadComponent() {
MultiFileMemoryBuffer buffer = new MultiFileMemoryBuffer();
Upload upload = new Upload(buffer);
upload.setAcceptedFileTypes(".txt", ".md", ".pdf");
upload.addSucceededListener(handleUpload(buffer));
upload.setWidthFull();
List<String> savedResources = jdbcTemplate.queryForList("SELECT distinct metadata->>'source' FROM vector_store", String.class);
uploadedFiles.setItems(savedResources);
return upload;
}
Diese Methode erstellt eine Upload-Komponente, die nur .txt, .md und .pdf-Dateien akzeptiert. Wir verarbeiten den Upload mit der Methode handleUpload und setzen die Breite der Komponente auf volle Breite. Da wir PostgreSQL verwenden, können wir einfach das JdbcTemplate einbinden, um die Datenbank abzufragen und die Liste der hochgeladenen Dateien zu erhalten, sodass wir die zuvor hochgeladenen Dateien laden können. Sobald wir die Liste der hochgeladenen Dateien haben, können wir sie in einer MultiSelectComboBox-Komponente anzeigen, damit wir die Datei auswählen können, mit der wir chatten möchten. Zur Vereinfachung werden wir keine Kontexte für mehrere Benutzer behandeln. Daher stehen alle geladenen Dateien allen Benutzern zur Verfügung. Um mehrere Benutzer zu verwalten, können wir die Dateien nach Benutzer-ID oder Sitzungs-ID filtern.
Weiter geht’s mit der Implementierung der handleUpload-Methode:
private ComponentEventListener<SucceededEvent> handleUpload(MultiFileMemoryBuffer buffer) {
return event -> {
String fileName = event.getFileName();
TikaDocumentReader tikaReader = new TikaDocumentReader(new InputStreamResource(buffer.getInputStream(fileName)));
TextSplitter textSplitter = new TokenTextSplitter();
List<Document> parsedDocuments = textSplitter.apply(tikaReader.get());
parsedDocuments.forEach(document -> document.getMetadata().put("source", fileName));
vectorStore.accept(parsedDocuments);
uploadedFiles.getListDataView().addItem(fileName);
};
}
Diese Methode erstellt einen TikaDocumentReader und einen TokenTextSplitter, um das Dokument zu analysieren und in Abschnitte zu unterteilen. Anschließend speichern wir die Embeddings in der Datenbank und fügen den Dateinamen der Liste der hochgeladenen Dateien hinzu. Das Speichern des Dateinamens ermöglicht es uns, die Datenbank nach den ähnlichsten Embeddings zur Benutzeranfrage abzufragen.
Der vectorStore ist eine Instanz von VectorStore, die wir mithilfe von Springs Dependency Injection einfügen. Sofern wir kein benutzerdefiniertes Verhalten wünschen, können wir die Standardimplementierung verwenden, die von Spring AI bereitgestellt wird. Wir können die Implementierung der VectorStore-Schnittstelle problemlos austauschen, um ein anderes Datenbank- oder Speichersystem zu verwenden. Hinter den Kulissen nutzt der VectorStore OpenAI, um die Embeddings zu generieren und in der Datenbank zu speichern. Wir können verschiedene Embedding-Generatoren und Speichersysteme über die Datei application.properties konfigurieren.
Als nächstes lassen Sie uns die Upload-Komponente und den Auswahlbereich der hochgeladenen Dateien in der Hauptansicht anzeigen:
private final transient VectorStore vectorStore;
private final transient JdbcTemplate jdbcTemplate;
private final MultiSelectComboBox<String> uploadedFiles;
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout);
}
Wenn wir die Anwendung jetzt ausführen, sollten wir die Upload-Komponente und die Liste der hochgeladenen Dateien sehen:

Wir können jetzt das Dokument hochladen und die Anwendung es verarbeiten lassen. Sobald das Dokument verarbeitet ist, können wir die Liste der hochgeladenen Dateien im Multi-Select-Kombinationsfeld überprüfen.
6. Erstellen des ChatService
Nun, da wir das Dokument hochgeladen haben, möchten wir eine Chat-ähnliche Ansicht erstellen, die es uns ermöglicht, damit zu interagieren.
Bevor wir mit der grafischen Benutzeroberfläche arbeiten, möchten wir die Chat-Logik von der Ansicht in einem Spring-Service abstrahieren. Kurz gesagt, wir möchten eine Methode, die eine Eingabeaufforderung, eine Konversations-ID und eine Liste von Quelldateien entgegennimmt und die Antwort des Chatbots zurückgibt.
Zuerst definieren wir eine Systemaufforderung, die das LLM-Modell anleiten wird, wie es auf die Benutzeranfrage reagieren soll:
private static final String SYSTEM_PROMPT = """
You are an expert in various domains, capable of providing detailed and accurate information.
Using the context provided by recent conversations, answer the new question in a concise and informative manner.
Limit your answer to a maximum of three sentences.
Your response is always a simple text.
""";
Zweitens werden wir einen In-Memory-Chatverlauf mithilfe der ChatMemory-Abstraktion von Spring AI erstellen. Dies ermöglicht uns, den Gesprächsverlauf im Speicher zu behalten, sodass wir ihn nutzen können, um dem Chatbot historischen Kontext zu bieten und den Gesprächsverlauf zu laden, wenn der Benutzer zum Chat zurückkehrt.
Drittens werden wir einen QuestionAnswerAdvisor an den Chat-Client anhängen, damit wir die Datenbank nach den ähnlichsten Embeddings zur Benutzeranfrage basierend auf den Quelldateien abfragen können. Dieser Advisor wird den VectorStore verwenden, um die Datenbank abzufragen und die ähnlichsten Embeddings zur Benutzeranfrage zu erhalten:
private final ChatClient chatClient;
private final ChatMemory chatMemory;
public ChatService(ChatClient.Builder chatClientBuilder,
VectorStore vectorStore) {
chatMemory = new InMemoryChatMemory();
QuestionAnswerAdvisor questionAnswerAdvisor = new QuestionAnswerAdvisor(vectorStore);
this.chatClient = chatClientBuilder
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
questionAnswerAdvisor,
new SimpleLoggerAdvisor())
.build();
}
Außerdem verwenden wir zur Vereinfachung den SimpleLoggerAdvisor, um den Chatverlauf in der Konsole zu protokollieren. Darüber hinaus bietet Spring AI diese Abstraktion an, um es uns zu ermöglichen, Advisors einfach auszutauschen und das Verhalten des Chatbots anzupassen. Wir können uns Advisors als ein Chain of Responsibility-Muster vorstellen, bei dem jeder Advisor die Nachricht ändern kann, bevor sie an das LLM-Modell gesendet wird—ähnlich wie Filter in Spring Security. Am Ende des Konstruktors setzen wir alle Teile zusammen und haben eine ChatClient-Instanz, die wir in unserem ChatService verwenden können.
Denken wir daran, dass wir hier nicht spezifizieren, welches Modell verwendet werden soll. Wir wissen, dass wir OpenAI als einzige Abhängigkeit dieses Projekts definiert haben, daher wird der ChatClient OpenAI als LLM-Modell verwenden. Wenn wir ein anderes Modell verwenden möchten, müssen wir zuerst die Abhängigkeit in der pom.xml-Datei hinzufügen und dann das korrekte Modell mithilfe der @Qualifier-Annotation injizieren. Alternativ können wir den ChatClient explizit mit dem richtigen Modell erstellen:
var openAiApi = new OpenAiApi(System.getenv("OPENAI_API_KEY"));
var openAiChatOptions = OpenAiChatOptions.builder()
.withModel("gpt-3.5-turbo")
.withTemperature(0.4)
.withMaxTokens(200)
.build();
var chatModel = new OpenAiChatModel(this.openAiApi, this.openAiChatOptions);
Wir müssen uns keine Sorgen über die Modellkonfiguration machen, da wir sie bereits in der Datei application.properties festgelegt haben. Der ChatClient wird das Modell verwenden, das wir in der Konfigurationsdatei angegeben haben.
Schließlich erstellen wir eine Methode, die eine Frage, eine Konversations-ID und eine Liste von Quelldateien entgegennimmt und die Antwort des Chatbots zurückgibt:
public ChatResponse ask(String question, String conversationId, Set<String> sourceFiles) {
String sourcesFilter = String.format("source in ['%s']", String.join("','", sourceFiles));
return chatClient.prompt()
.user(question)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.advisors(spec -> spec.param(FILTER_EXPRESSION, sourcesFilter))
.call()
.chatResponse();
}
Das erste, was wir tun, ist, den Filterausdruck zu erstellen, den wir verwenden werden, um die Einbettungen nach den Quelldateien zu filtern. Dann geben wir dem ChatClient die Benutzerfrage, die Gesprächs-ID und den Filterausdruck als Eingabe. Schließlich geben wir die Chat-Antwort zurück.
Die Konfiguration der Advisors im Konstruktor ist die halbe Miete. Der andere Teil der korrekten Nutzung der Advisors besteht darin, dass wir bei jeder Eingabeaufforderung die erforderlichen Parameter übergeben müssen. In diesem Fall übergeben wir die Konversations-ID an den MessageChatMemoryAdvisor und den Filterausdruck an den QuestionAnswerAdvisor. Wie diese Advisors diese Parameter verwenden, hängt von der Implementierung des jeweiligen Advisors ab. Zum Beispiel nutzen wir das source-Metadatenfeld, um die Einbettungen nach der Quelldatei zu filtern. Intern wird der QuestionAnswerAdvisor diese Information verwenden, wenn er den VectorStore abfragt. Dieser Advisor bietet eine einfache Möglichkeit, die Einbettungen nach der Quelldatei zu filtern. Wir können auch komplexere Filter verwenden, um die Einbettungen nach Benutzer-ID, Sitzungs-ID oder einem anderen Metadatenfeld zu filtern.
7. ChatView erstellen
Nun, da wir den Chat-Service haben, können wir eine Ansicht erstellen, die es uns ermöglicht, mit dem Dokument zu chatten.
Zuerst erstellen wir ein einfaches TextField, um die Benutzereingabe aufzunehmen:
private TextField createMessageField() {
TextField questionField = new TextField("Ask your question");
questionField.setWidthFull();
return questionField;
}
Dann erstellen wir einen Button, der es uns ermöglicht, die Nachricht an unser LLM-Modell zu senden:
private Button createSendButton(ChatService chatService, TextField messageField) {
Button askButton = new Button(VaadinIcon.PAPERPLANE.create(), handleNewMessageRequest(chatService, messageField, chatContainer));
askButton.addThemeVariants(ButtonVariant.LUMO_PRIMARY);
askButton.addClickShortcut(Key.ENTER);
return askButton;
}
Wir verwenden die Methode handleNewMessageRequest, um die Benutzeranfrage zu bearbeiten. Kurz gesagt, wir lesen die Benutzereingabe, fügen die Benutzernachricht dem Chat-Container hinzu, fragen den Chat-Service nach der Antwort und fügen die Chatbot-Antwort dem Chat-Container hinzu, der ein VerticalLayout ist:
private ComponentEventListener<ClickEvent<Button>> handleNewMessageRequest(ChatService service, TextField messageField, VerticalLayout chatContainer) {
return _ -> {
if (StringUtils.isBlank(messageField.getValue())) {
Notification.show("Please enter a question");
} else {
chatContainer.add(getMessageBlock(new UserMessage(messageField.getValue())));
AssistantMessage answer = service.ask(messageField.getValue(),
UI.getCurrent().getSession().getSession().getId(), uploadedFiles.getValue())
.getResult().getOutput();
chatContainer.add(getMessageBlock(answer));
}
};
}
Wir verwenden die Sitzungs-ID als Gesprächs-ID, um das Management des Verlaufs zu vereinfachen. Um den Verlauf zu entfernen, erstellen wir eine Schaltfläche zum Löschen, die den Gesprächsverlauf aus der ChatMemory-Instanz entfernt:
private Button createClearHistoryButton() {
Button clearHistory = new Button(VaadinIcon.TRASH.create(), handleSessionClear());
clearHistory.addThemeVariants(ButtonVariant.LUMO_ERROR);
return clearHistory;
}
Nun werden wir alle Komponenten in der MainView zusammenfügen:
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate,
ChatService chatService) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
this.chatService = chatService;
chatContainer = createChatContainer();
setSizeFull();
TextField messageField = createMessageField();
Button askButton = createSendButton(chatService, messageField);
Button clearHistory = createClearHistoryButton();
HorizontalLayout messageBar = new HorizontalLayout(messageField, askButton, clearHistory);
messageBar.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
messageBar.setWidthFull();
messageBar.setFlexGrow(1, messageField);
Scroller scroller = new Scroller(chatContainer);
scroller.setWidthFull();
VerticalLayout chatBox = new VerticalLayout();
chatBox.setMaxHeight(80, Unit.PERCENTAGE);
chatBox.add(scroller, messageBar);
chatBox.setFlexGrow(1, scroller);
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout, new Hr(), chatBox);
setFlexGrow(1, chatBox);
setWidthFull();
}
Wenn wir die Anwendung jetzt ausführen, sollten wir die Chat-Ansicht sehen, die es uns ermöglicht, mit dem Dokument zu chatten:
8. Testen der Anwendung
Lassen Sie uns die Anwendung testen, indem wir ein Dokument hochladen und mit dem Chatbot chatten. Zuvor haben wir ein Dokument mit Anweisungen zum Installieren eines MongoDB-Servers hochgeladen.
Zuerst fragen wir den Chatbot, wie wir den MongoDB-Server sichern können, ohne die Quelldatei anzugeben:
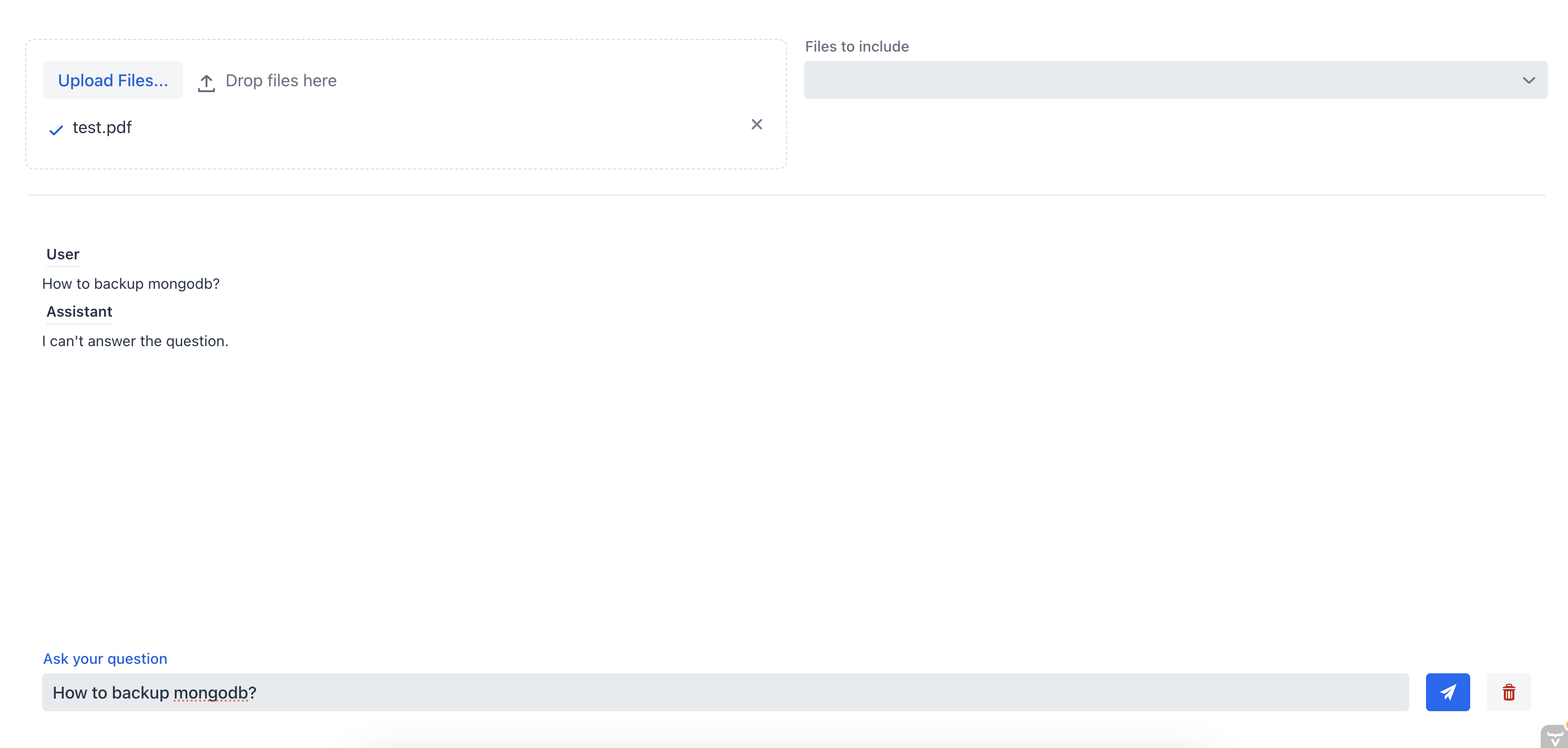
Wie wir sehen können, ist der Chatbot nicht in der Lage, eine gute Antwort zu geben, da ihm der Kontext des Dokuments fehlt. Jetzt lassen Sie uns dem Chatbot die gleiche Frage stellen, aber dieses Mal werden wir die Quelldatei aus dem Multi-Select-Kombinationsfeld auswählen:
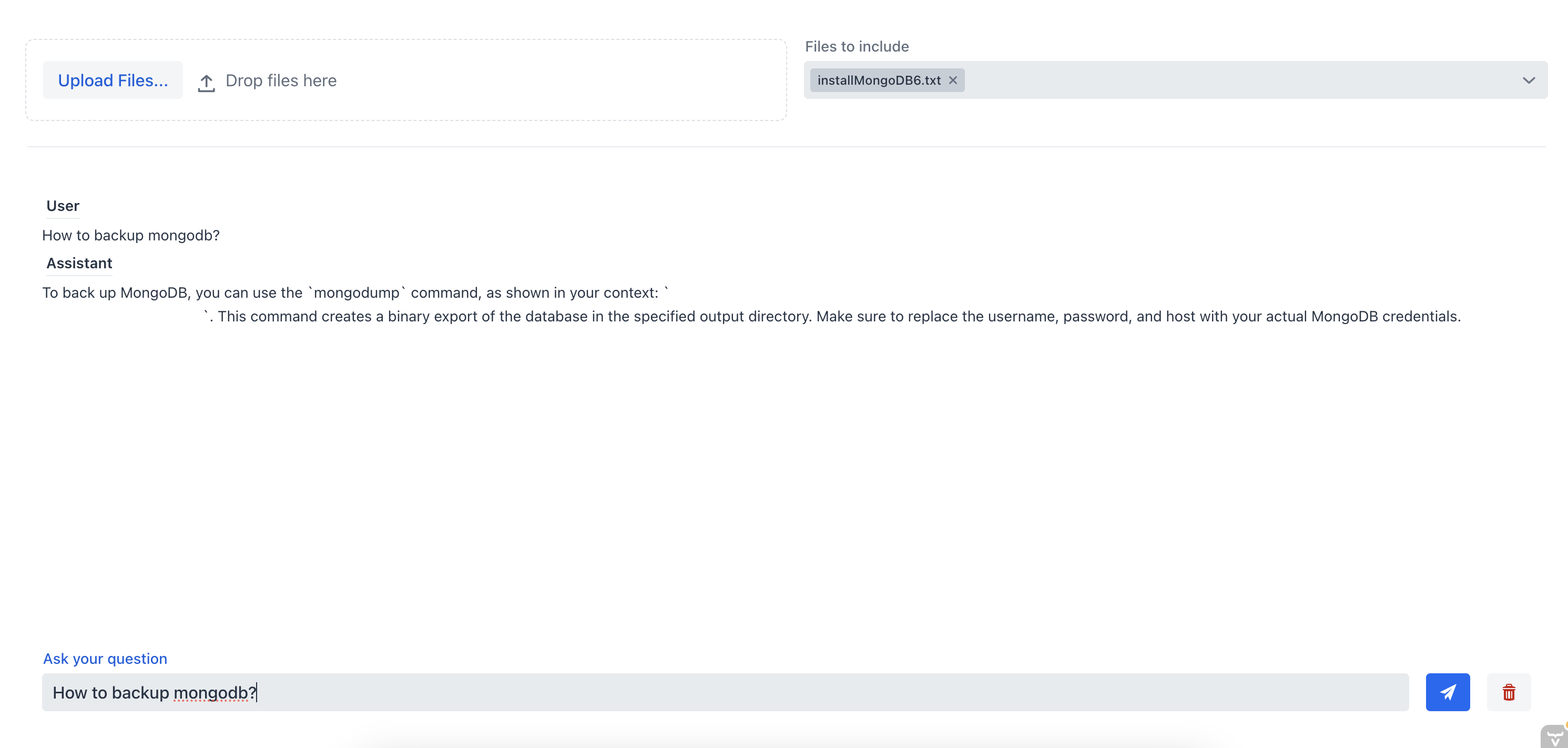
In diesem Fall konnte der Chat-Assistent die richtige Antwort geben, weil ihm der Kontext des Dokuments vorlag. Dies zeigt die Effektivität des RAG-Chatbots; indem wir dem Chatbot Kontext bereitstellen, können wir die relevantesten Informationen aus einem oder mehreren Dokumenten erhalten.
9. Fazit
In diesem Tutorial haben wir gelernt, wie man ein komplettes RAG-Chatbot-System mit Spring AI erstellt, das es uns ermöglicht, mit einem hochgeladenen Dokument zu chatten. Wir haben den TikaDocumentReader verwendet, um das Dokument zu parsen und dann Teile des Dokuments an OpenAI zu senden, um die Embeddings zu erstellen. Diese Embeddings werden in einer Postgres-Datenbank mit pgvector gespeichert, und wir können die Datenbank abfragen, um die Embeddings zu erhalten, die der Benutzeranfrage am ähnlichsten sind. Sobald wir diese Informationen haben, können wir eine Unterhaltung mit unserem Chatbot beginnen und die relevantesten Informationen aus dem Dokument erhalten.
Wir können den vollständigen Code auf GitHub ansehen.