


1. Descripción general
En este tutorial, aprenderemos cómo crear un sistema completo de chatbot RAG con Spring AI que nos permite chatear con los documentos que subimos.
En resumen, usaremos TikaDocumentReader para analizar el documento, enviar fragmentos a OpenAI y crear las embeddings. Luego, estas embeddings se almacenan en una base de datos Postgres usando PGvector, y podemos consultar la base de datos para obtener las embeddings que son más similares a la consulta del usuario. Una vez que tenemos esta información, podemos iniciar una conversación con nuestro chatbot y obtener la información más relevante del documento.
Comencemos creando un nuevo proyecto de Spring AI con Vaadin.
2. Dependencias Requeridas
Usaremos el Spring Initializr para crear un nuevo proyecto con las siguientes dependencias:
- Vaadin
- OpenAI
- Tika Document Reader
- PGvector Vector Database
- Docker Compose Support (opcional)
Para ejecutarse correctamente, la aplicación en este tutorial utilizará Docker para crear una instancia de Postgres configurada con las extensiones PGvector. De lo contrario, podemos usar una instancia de Postgres de nuestra elección e instalar la extensión PGvector manualmente.
3. Configurar las Propiedades de la Aplicación
Antes de escribir cualquier lógica de negocio, necesitamos configurar la aplicación para poder seleccionar la clave de API de OpenAI correcta y los modelos:
spring.ai.openai.api-key=YOUR_OPENAI_API_KEY
spring.ai.openai.chat.options.model=gpt-4o-mini
Aquí, hemos decidido usar el modelo gpt-4o-mini, pero podemos cambiarlo a cualquier otro modelo disponible en OpenAI.
A continuación, configuraremos nuestra tienda de vectores:
spring.ai.vectorstore.pgvector.initialize-schema=true
spring.ai.vectorstore.pgvector.index-type=HNSW
spring.ai.vectorstore.pgvector.distance-type=COSINE_DISTANCE
spring.ai.vectorstore.pgvector.dimensions=1536
Aquí, hemos decidido utilizar el tipo de índice HNSW y COSINE_DISTANCE como el tipo de distancia. También establecemos las dimensiones en 1536, ya que esta es la dimensión de las embeddings generadas por OpenAI.
A continuación, configuramos un archivo docker-compose para iniciar una instancia de Postgres con las extensiones PGvector:
services:
pgvector:
image: 'pgvector/pgvector:pg16'
environment:
- 'POSTGRES_DB=mydatabase'
- 'POSTGRES_PASSWORD=secret'
- 'POSTGRES_USER=myuser'
labels:
- "org.springframework.boot.service-connection=postgres"
ports:
- '5432'
Este archivo es un archivo docker-compose sencillo que inicia una instancia de Postgres con la imagen pgvector/pgvector:pg16 y expone el puerto 5432 a la máquina anfitriona. Decidimos usar esta imagen porque ya tiene la extensión pgvector instalada y configurada. Además, vamos a indicarle a la aplicación que detenga la base de datos cuando la aplicación se detenga:
spring.docker.compose.stop.command=stop
Al haber añadido el soporte para Docker Compose, nuestra aplicación gestionará la creación de la base de datos utilizando este archivo de configuración e inyectará las propiedades correctas para conectarse a la base de datos. Si decidimos usar una base de datos diferente, podemos configurar las propiedades de conexión en el archivo application.properties como en una aplicación habitual de Spring Data JPA:
spring.datasource.url=jdbc:postgresql://localhost:5432/mydatabase
spring.datasource.username=myuser
spring.datasource.password=secret
spring.datasource.driver-class-name=org.postgresql.Driver
4. Crear una Aplicación Vaadin
Ahora que nuestra configuración está completa, crearemos una aplicación Vaadin que nos permita subir un documento y comenzar una conversación con el chatbot.
Creemos el punto de entrada principal de nuestra aplicación:
@SpringBootApplication
public class RagSpringAiApplication implements AppShellConfigurator {
public static void main(String[] args) {
SpringApplication.run(RagSpringAiApplication.class, args);
}
}
Estamos utilizando la interfaz AppShellConfigurator para configurar el shell de la aplicación como la aplicación estándar de Vaadin.
A continuación, crearemos un diseño simple para verificar si todo está funcionando:
@Route("")
@PageTitle("Chatbot")
public class MainView extends VerticalLayout {
public MainView() {
add(new H1("Hello, World!"));
}
}
Si todo está funcionando correctamente, deberíamos ver una página sencilla con el título Hello, World!:
{kind=link}
Ahora que tenemos la estructura básica de una aplicación sencilla, podemos comenzar a construir todos los servicios y componentes que necesitamos.
5. Crear Componente de Subida
Lo primero que necesitamos es un componente que nos permita subir un documento al servidor. Para esto, usaremos el componente Upload de Vaadin y lo extenderemos para que se ajuste a nuestras necesidades:
private Upload createUploadComponent() {
MultiFileMemoryBuffer buffer = new MultiFileMemoryBuffer();
Upload upload = new Upload(buffer);
upload.setAcceptedFileTypes(".txt", ".md", ".pdf");
upload.addSucceededListener(handleUpload(buffer));
upload.setWidthFull();
List<String> savedResources = jdbcTemplate.queryForList("SELECT distinct metadata->>'source' FROM vector_store", String.class);
uploadedFiles.setItems(savedResources);
return upload;
}
Este método crea un componente Upload que solo acepta archivos .txt, .md y .pdf. Gestionamos la carga utilizando el método handleUpload y establecemos el ancho del componente a completo. Como estamos utilizando PostgreSQL, podemos inyectar fácilmente el JdbcTemplate para consultar la base de datos y obtener la lista de archivos cargados, de modo que podamos cargar los archivos previamente subidos. Una vez que tenemos la lista de archivos cargados, podemos mostrarlos en un componente MultiSelectComboBox para que podamos seleccionar el archivo con el que queremos chatear. Para simplificar, no vamos a manejar contextos para múltiples usuarios. Por lo tanto, todos los archivos cargados estarán disponibles para todos los usuarios. Para manejar múltiples usuarios, podemos filtrar los archivos por id de usuario o id de sesión.
Continuemos, implementemos el método handleUpload:
private ComponentEventListener<SucceededEvent> handleUpload(MultiFileMemoryBuffer buffer) {
return event -> {
String fileName = event.getFileName();
TikaDocumentReader tikaReader = new TikaDocumentReader(new InputStreamResource(buffer.getInputStream(fileName)));
TextSplitter textSplitter = new TokenTextSplitter();
List<Document> parsedDocuments = textSplitter.apply(tikaReader.get());
parsedDocuments.forEach(document -> document.getMetadata().put("source", fileName));
vectorStore.accept(parsedDocuments);
uploadedFiles.getListDataView().addItem(fileName);
};
}
Este método crea un TikaDocumentReader y un TokenTextSplitter para analizar el documento y dividirlo en fragmentos. Luego, almacenamos las embeddings en la base de datos y añadimos el nombre del archivo a la lista de archivos subidos. Guardar el nombre del archivo nos permite consultar la base de datos para encontrar las embeddings más similares a la consulta del usuario.
El vectorStore es una instancia de VectorStore que inyectamos usando la inyección de dependencias de Spring. A menos que queramos un comportamiento personalizado, podemos usar la implementación predeterminada proporcionada por Spring AI. Podemos intercambiar fácilmente la implementación de la interfaz VectorStore para usar una base de datos o sistema de almacenamiento diferente. El VectorStore, detrás de escena, usará OpenAI para generar las embeddings y almacenarlas en la base de datos. Podemos configurar diferentes generadores de embeddings y sistemas de almacenamiento usando el archivo application.properties.
A continuación, mostremos el componente de carga y el selector de los archivos subidos en la vista principal:
private final transient VectorStore vectorStore;
private final transient JdbcTemplate jdbcTemplate;
private final MultiSelectComboBox<String> uploadedFiles;
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout);
}
Si ejecutamos la aplicación ahora, deberíamos ver el componente de carga y la lista de archivos cargados:

Ahora podemos subir el documento y dejar que la aplicación lo procese. Una vez que el documento esté procesado, podemos revisar la lista de archivos subidos en el cuadro combinado de selección múltiple.
6. Crear ChatService
Ahora que tenemos el documento cargado, queremos crear una vista similar a un chat que nos permita interactuar con él.
Antes de trabajar con la interfaz gráfica de usuario, queremos abstraer la lógica del chat de la vista en un servicio de Spring. En resumen, queremos un método que reciba un prompt, un id de conversación y una lista de archivos fuente, y que devuelva la respuesta del chatbot.
Primero, definiremos un system prompt que guiará al modelo LLM sobre cómo responder a la consulta del usuario:
private static final String SYSTEM_PROMPT = """
You are an expert in various domains, capable of providing detailed and accurate information.
Using the context provided by recent conversations, answer the new question in a concise and informative manner.
Limit your answer to a maximum of three sentences.
Your response is always a simple text.
""";
Segundo, crearemos un historial de chat en memoria utilizando la abstracción ChatMemory proporcionada por Spring AI. Esto nos permitirá persistir el historial de la conversación en memoria para que podamos usarlo para proporcionar contexto histórico al chatbot y cargar el historial de la conversación cuando el usuario regrese al chat.
Tercero, adjuntaremos un QuestionAnswerAdvisor al cliente de chat para que podamos consultar la base de datos en busca de los embeddings más similares a la consulta del usuario basándonos en los archivos fuente. Este asesor utilizará el VectorStore para consultar la base de datos y obtener los embeddings más similares a la consulta del usuario:
private final ChatClient chatClient;
private final ChatMemory chatMemory;
public ChatService(ChatClient.Builder chatClientBuilder,
VectorStore vectorStore) {
chatMemory = new InMemoryChatMemory();
QuestionAnswerAdvisor questionAnswerAdvisor = new QuestionAnswerAdvisor(vectorStore);
this.chatClient = chatClientBuilder
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
questionAnswerAdvisor,
new SimpleLoggerAdvisor())
.build();
}
Además, para simplificar, estamos usando el SimpleLoggerAdvisor para registrar el historial del chat en la consola. Además, Spring AI ofrece esta abstracción para permitirnos cambiar fácilmente de asesores y personalizar el comportamiento del chatbot. Podemos pensar en los asesores como un patrón de cadena de responsabilidad, donde cada asesor puede modificar el mensaje antes de enviarlo al modelo LLM, algo similar a los filtros en Spring Security. Al final del constructor, ensamblamos todas las piezas y tenemos una instancia de ChatClient que podemos usar dentro de nuestro ChatService.
Recuerden que no estamos especificando qué modelo usar aquí. Sabemos que definimos OpenAI como la única dependencia de este proyecto, por lo que el ChatClient utilizará OpenAI como el modelo LLM. Si queremos usar un modelo diferente, primero, necesitamos incluir la dependencia en el archivo pom.xml y luego inyectar el modelo correcto usando la anotación @Qualifier. Alternativamente, podemos construir explícitamente el ChatClient con el modelo correcto:
var openAiApi = new OpenAiApi(System.getenv("OPENAI_API_KEY"));
var openAiChatOptions = OpenAiChatOptions.builder()
.withModel("gpt-3.5-turbo")
.withTemperature(0.4)
.withMaxTokens(200)
.build();
var chatModel = new OpenAiChatModel(this.openAiApi, this.openAiChatOptions);
No necesitamos preocuparnos por la configuración del modelo porque ya la establecimos en el archivo application.properties. El ChatClient utilizará el modelo que colocamos en el archivo de configuración.
Finalmente, crearemos un método que tome una pregunta, un id de conversación y una lista de archivos fuente, y devuelva la respuesta del chatbot:
public ChatResponse ask(String question, String conversationId, Set<String> sourceFiles) {
String sourcesFilter = String.format("source in ['%s']", String.join("','", sourceFiles));
return chatClient.prompt()
.user(question)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.advisors(spec -> spec.param(FILTER_EXPRESSION, sourcesFilter))
.call()
.chatResponse();
}
Lo primero que hacemos es crear la expresión de filtro que utilizaremos para filtrar las embeddings por los archivos de origen. Luego, proporcionamos al ChatClient la pregunta del usuario, el id de la conversación y la expresión de filtro. Finalmente, devolvemos la respuesta del chat.
Haber configurado los advisors en el constructor es la mitad del trabajo. La otra parte de usar correctamente los advisors es que, con cada prompt, debemos pasarles los parámetros necesarios. En este caso, estamos pasando el id de la conversación al MessageChatMemoryAdvisor y la expresión de filtro al QuestionAnswerAdvisor. Cómo estos advisors utilizan estos parámetros depende de la implementación del propio advisor. Por ejemplo, estamos usando el campo de metadatos source para filtrar los embeddings por el archivo fuente. Internamente, el QuestionAnswerAdvisor usará esta información al consultar el VectorStore. Este advisor proporciona una manera sencilla de filtrar los embeddings por el archivo fuente. Podemos utilizar filtros más complejos para filtrar los embeddings por el id del usuario, id de sesión, o cualquier otro campo de metadatos.
7. Crear ChatView
Ahora que tenemos el servicio de chat, podemos crear una vista que nos permita chatear con el documento.
Primero, crearemos un TextField simple para ingresar el aviso del usuario:
private TextField createMessageField() {
TextField questionField = new TextField("Ask your question");
questionField.setWidthFull();
return questionField;
}
Luego, crearemos un Button que nos permitirá enviar el mensaje a nuestro modelo LLM:
private Button createSendButton(ChatService chatService, TextField messageField) {
Button askButton = new Button(VaadinIcon.PAPERPLANE.create(), handleNewMessageRequest(chatService, messageField, chatContainer));
askButton.addThemeVariants(ButtonVariant.LUMO_PRIMARY);
askButton.addClickShortcut(Key.ENTER);
return askButton;
}
Estamos utilizando el método handleNewMessageRequest para gestionar la solicitud del usuario. En resumen, leemos la entrada del usuario, añadimos el mensaje del usuario al contenedor del chat, solicitamos la respuesta al servicio de chat y agregamos la respuesta del chatbot al contenedor del chat, que es un VerticalLayout:
private ComponentEventListener<ClickEvent<Button>> handleNewMessageRequest(ChatService service, TextField messageField, VerticalLayout chatContainer) {
return _ -> {
if (StringUtils.isBlank(messageField.getValue())) {
Notification.show("Please enter a question");
} else {
chatContainer.add(getMessageBlock(new UserMessage(messageField.getValue())));
AssistantMessage answer = service.ask(messageField.getValue(),
UI.getCurrent().getSession().getSession().getId(), uploadedFiles.getValue())
.getResult().getOutput();
chatContainer.add(getMessageBlock(answer));
}
};
}
Estamos utilizando el session id como el conversation id para simplificar la gestión del historial. Para eliminar el historial, crearemos un botón de eliminación que quitará el historial de conversación de la instancia de ChatMemory:
private Button createClearHistoryButton() {
Button clearHistory = new Button(VaadinIcon.TRASH.create(), handleSessionClear());
clearHistory.addThemeVariants(ButtonVariant.LUMO_ERROR);
return clearHistory;
}
Ahora, reuniremos todos los componentes en el MainView:
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate,
ChatService chatService) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
this.chatService = chatService;
chatContainer = createChatContainer();
setSizeFull();
TextField messageField = createMessageField();
Button askButton = createSendButton(chatService, messageField);
Button clearHistory = createClearHistoryButton();
HorizontalLayout messageBar = new HorizontalLayout(messageField, askButton, clearHistory);
messageBar.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
messageBar.setWidthFull();
messageBar.setFlexGrow(1, messageField);
Scroller scroller = new Scroller(chatContainer);
scroller.setWidthFull();
VerticalLayout chatBox = new VerticalLayout();
chatBox.setMaxHeight(80, Unit.PERCENTAGE);
chatBox.add(scroller, messageBar);
chatBox.setFlexGrow(1, scroller);
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout, new Hr(), chatBox);
setFlexGrow(1, chatBox);
setWidthFull();
}
Si ejecutamos la aplicación ahora, deberíamos ver la vista de chat que nos permite chatear con el documento:
8. Probando la Aplicación
Probemos la aplicación subiendo un documento y charlando con el chatbot. Anteriormente, subimos un documento con instrucciones sobre cómo instalar un servidor MongoDB.
Primero, preguntemos al chatbot cómo hacer una copia de seguridad del servidor de MongoDB sin especificar el archivo de origen:
{kind=link}
Como podemos ver, el chatbot no es capaz de proporcionar una buena respuesta porque no tiene el contexto del documento. Ahora, hagamos la misma pregunta al chatbot, pero esta vez vamos a seleccionar el archivo fuente desde el cuadro combinado de selección múltiple:
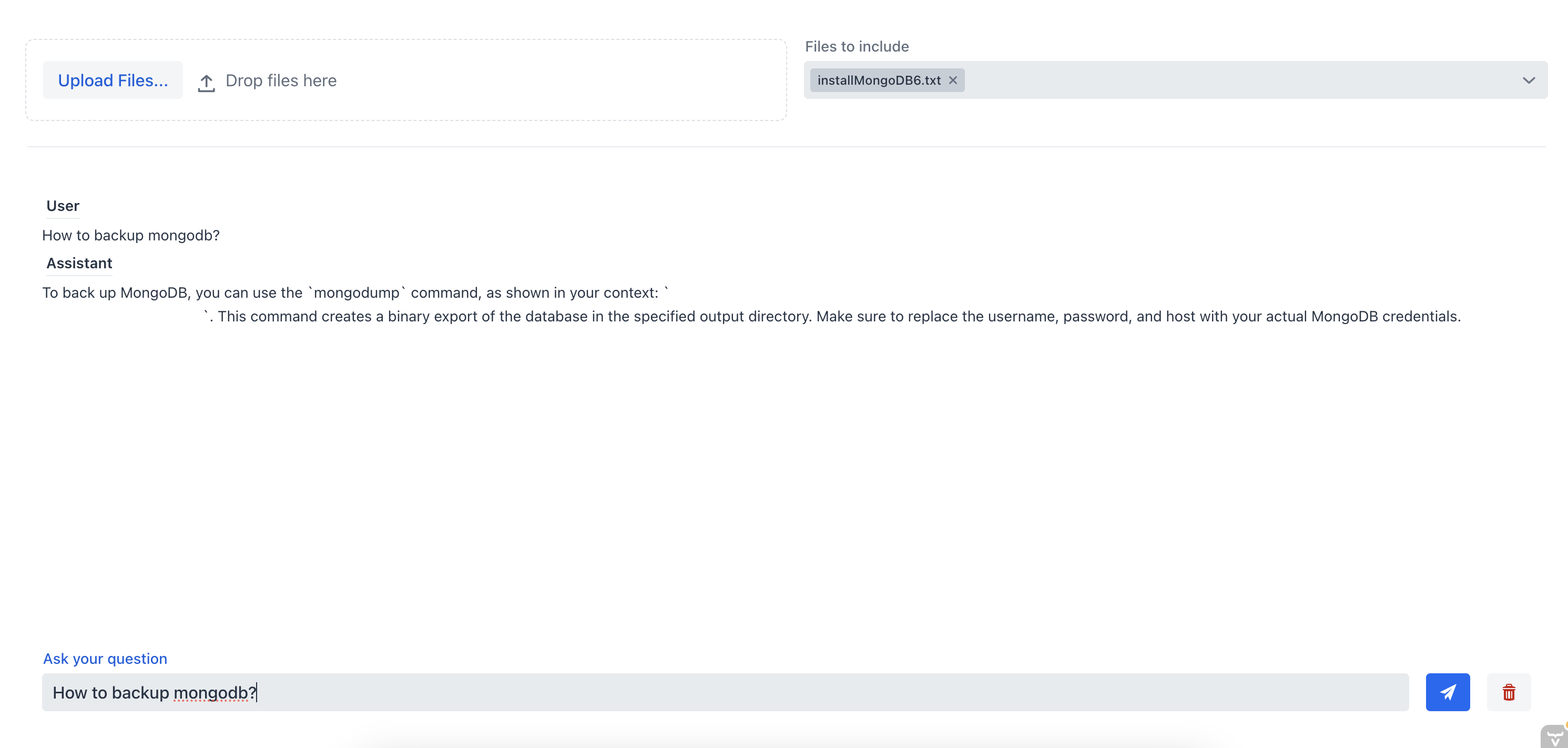
En este caso, el asistente de chat pudo proporcionar la respuesta correcta porque tenía el contexto del documento. Esto demuestra la efectividad del chatbot RAG; al proporcionar contexto al chatbot, podemos obtener la información más relevante de uno o varios documentos.
9. Conclusión
En este tutorial, aprendimos cómo crear un sistema de chatbot RAG completo con Spring AI que nos permite chatear con un documento que subimos. Usamos TikaDocumentReader para analizar el documento y luego enviamos fragmentos del documento a OpenAI para crear los embeddings. Estos embeddings se almacenan en una base de datos Postgres utilizando pgvector, y podemos consultar la base de datos para obtener los embeddings que son más similares a la consulta del usuario. Una vez que tenemos esta información, podemos iniciar una conversación con nuestro chatbot y obtener la información más relevante del documento.
Podemos buscar el código completo en Github.