


1. Aperçu
Dans ce tutoriel, nous allons apprendre à créer un système de chatbot RAG complet avec Spring AI qui nous permet de discuter avec les documents que nous téléchargeons.
En bref, nous utiliserons TikaDocumentReader pour analyser le document, envoyer des morceaux à OpenAI, et créer les embeddings. Ensuite, ces embeddings sont stockés dans une base de données Postgres en utilisant PGvector, et nous pouvons interroger la base de données pour obtenir les embeddings les plus similaires à la requête de l’utilisateur. Une fois que nous avons cette information, nous pouvons entamer une conversation avec notre chatbot et obtenir les informations les plus pertinentes du document.
Commençons par créer un nouveau projet Spring AI avec Vaadin.
2. Dépendances Requises
Nous allons utiliser le Spring Initializr pour créer un nouveau projet avec les dépendances suivantes :
- Vaadin
- OpenAI
- Tika Document Reader
- PGvector Vector Database
- Docker Compose Support (optionnel)
Pour fonctionner correctement, l’application de ce tutoriel utilisera Docker pour créer une instance de Postgres configurée avec les extensions PGvector. Sinon, nous pouvons utiliser une instance de Postgres de notre choix et installer manuellement l’extension PGvector.
3. Configurer les propriétés de l’application
Avant d’écrire toute logique métier, nous devons configurer l’application afin de pouvoir sélectionner la clé API OpenAI et les modèles appropriés :
spring.ai.openai.api-key=YOUR_OPENAI_API_KEY
spring.ai.openai.chat.options.model=gpt-4o-mini
Ici, nous avons décidé d’utiliser le modèle gpt-4o-mini, mais nous pouvons le changer pour n’importe quel autre modèle disponible chez OpenAI. Ensuite, nous allons configurer notre magasin de vecteurs :
spring.ai.vectorstore.pgvector.initialize-schema=true
spring.ai.vectorstore.pgvector.index-type=HNSW
spring.ai.vectorstore.pgvector.distance-type=COSINE_DISTANCE
spring.ai.vectorstore.pgvector.dimensions=1536
Ici, nous avons décidé d’utiliser le type d’index HNSW et COSINE_DISTANCE comme type de distance. Nous avons également défini les dimensions à 1536, car c’est la dimension des embeddings générés par OpenAI.
Ensuite, nous configurons un fichier docker-compose pour démarrer une instance Postgres avec les extensions PGvector :
services:
pgvector:
image: 'pgvector/pgvector:pg16'
environment:
- 'POSTGRES_DB=mydatabase'
- 'POSTGRES_PASSWORD=secret'
- 'POSTGRES_USER=myuser'
labels:
- "org.springframework.boot.service-connection=postgres"
ports:
- '5432'
Ce fichier est un fichier docker-compose simple qui démarre une instance Postgres avec l’image pgvector/pgvector:pg16 et expose le port 5432 à la machine hôte. Nous avons décidé d’utiliser cette image car elle a déjà l’extension pgvector installée et configurée. De plus, nous allons indiquer à l’application d’arrêter la base de données lorsque l’application s’arrête :
spring.docker.compose.stop.command=stop
En ajoutant la prise en charge de Docker Compose, notre application gérera la création de la base de données en utilisant ce fichier de configuration et injectera les propriétés correctes pour se connecter à la base de données. Si nous décidons d’utiliser une base de données différente, nous pouvons configurer les propriétés de connexion dans le fichier application.properties comme dans une application Spring Data JPA habituelle :
spring.datasource.url=jdbc:postgresql://localhost:5432/mydatabase
spring.datasource.username=myuser
spring.datasource.password=secret
spring.datasource.driver-class-name=org.postgresql.Driver
4. Créer une Application Vaadin
Maintenant que notre configuration est terminée, nous allons créer une application Vaadin qui nous permettra de télécharger un document et de démarrer une conversation avec le chatbot.
Créons le point d’entrée principal de notre application :
@SpringBootApplication
public class RagSpringAiApplication implements AppShellConfigurator {
public static void main(String[] args) {
SpringApplication.run(RagSpringAiApplication.class, args);
}
}
Nous utilisons l’interface AppShellConfigurator pour configurer l’enveloppe de l’application comme une application Vaadin standard.
Ensuite, nous allons créer une mise en page simple pour vérifier si tout fonctionne :
@Route("")
@PageTitle("Chatbot")
public class MainView extends VerticalLayout {
public MainView() {
add(new H1("Hello, World!"));
}
}
Si tout fonctionne correctement, nous devrions voir une page simple avec le titre Hello, World! :

Maintenant que nous avons l’ossature d’une application simple, nous pouvons commencer à construire tous les services et composants dont nous avons besoin.
5. Créer un Composant de Téléchargement
La première chose dont nous avons besoin est un composant qui nous permet de télécharger un document sur le serveur. Pour cela, nous allons utiliser le composant Upload de Vaadin et l’étendre pour répondre à nos besoins :
private Upload createUploadComponent() {
MultiFileMemoryBuffer buffer = new MultiFileMemoryBuffer();
Upload upload = new Upload(buffer);
upload.setAcceptedFileTypes(".txt", ".md", ".pdf");
upload.addSucceededListener(handleUpload(buffer));
upload.setWidthFull();
List<String> savedResources = jdbcTemplate.queryForList("SELECT distinct metadata->>'source' FROM vector_store", String.class);
uploadedFiles.setItems(savedResources);
return upload;
}
Cette méthode crée un composant Upload qui n’accepte que les fichiers .txt, .md, et .pdf. Nous gérons le téléchargement en utilisant la méthode handleUpload et réglons la largeur du composant à pleine. Comme nous utilisons PostgreSQL, nous pouvons facilement injecter le JdbcTemplate pour interroger la base de données et obtenir la liste des fichiers téléchargés afin que nous puissions charger les fichiers précédemment téléchargés. Une fois que nous avons la liste des fichiers téléchargés, nous pouvons les afficher dans un composant MultiSelectComboBox afin de pouvoir sélectionner le fichier avec lequel nous voulons discuter. Pour simplifier, nous n’allons pas gérer les contextes pour plusieurs utilisateurs. Par conséquent, tous les fichiers chargés seront disponibles pour tous les utilisateurs. Pour gérer plusieurs utilisateurs, nous pouvons filtrer les fichiers par id utilisateur ou id de session.
Passons à l’implémentation de la méthode handleUpload :
private ComponentEventListener<SucceededEvent> handleUpload(MultiFileMemoryBuffer buffer) {
return event -> {
String fileName = event.getFileName();
TikaDocumentReader tikaReader = new TikaDocumentReader(new InputStreamResource(buffer.getInputStream(fileName)));
TextSplitter textSplitter = new TokenTextSplitter();
List<Document> parsedDocuments = textSplitter.apply(tikaReader.get());
parsedDocuments.forEach(document -> document.getMetadata().put("source", fileName));
vectorStore.accept(parsedDocuments);
uploadedFiles.getListDataView().addItem(fileName);
};
}
Cette méthode crée un TikaDocumentReader et un TokenTextSplitter pour analyser le document et le diviser en morceaux. Ensuite, nous stockons les embeddings dans la base de données et ajoutons le nom du fichier à la liste des fichiers téléchargés. Sauvegarder le nom du fichier nous permet d’interroger la base de données pour obtenir les embeddings les plus similaires à la requête de l’utilisateur.
Le vectorStore est une instance de VectorStore que nous injectons en utilisant l’injection de dépendance de Spring. À moins que nous ne souhaitions un comportement personnalisé, nous pouvons utiliser l’implémentation par défaut fournie par Spring AI. Nous pouvons facilement remplacer l’implémentation de l’interface VectorStore pour utiliser une base de données ou un système de stockage différent. En coulisses, le VectorStore utilisera OpenAI pour générer les embeddings et les stocker dans la base de données. Nous pouvons configurer différents générateurs d’embeddings et systèmes de stockage en utilisant le fichier application.properties.
Ensuite, affichons le composant de téléchargement et le sélecteur des fichiers téléchargés dans la vue principale :
private final transient VectorStore vectorStore;
private final transient JdbcTemplate jdbcTemplate;
private final MultiSelectComboBox<String> uploadedFiles;
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout);
}
Si nous exécutons l’application maintenant, nous devrions voir le composant de téléchargement et la liste des fichiers téléchargés :

Nous pouvons maintenant télécharger le document et laisser l’application le traiter. Une fois le document traité, nous pouvons vérifier la liste des fichiers téléchargés dans la boîte combo multi-sélection.
6. Créer ChatService
Maintenant que nous avons téléchargé le document, nous souhaitons créer une vue de type chat qui nous permet d’interagir avec celui-ci.
Avant de travailler avec l’interface utilisateur graphique, nous souhaitons abstraire la logique du chat de la vue dans un service Spring. En résumé, nous voulons une méthode qui prenne un prompt, un identifiant de conversation, et une liste de fichiers sources, et qui retourne la réponse du chatbot.
Tout d’abord, nous allons définir une invite système qui guidera le modèle LLM sur la manière de répondre à la requête de l’utilisateur :
private static final String SYSTEM_PROMPT = """
You are an expert in various domains, capable of providing detailed and accurate information.
Using the context provided by recent conversations, answer the new question in a concise and informative manner.
Limit your answer to a maximum of three sentences.
Your response is always a simple text.
""";
Ensuite, nous créerons un historique de chat en mémoire en utilisant l’abstraction ChatMemory fournie par Spring AI. Cela nous permettra de conserver l’historique de la conversation en mémoire afin que nous puissions l’utiliser pour fournir un contexte historique au chatbot et charger l’historique de la conversation lorsque l’utilisateur revient au chat.
Troisièmement, nous attacherons un QuestionAnswerAdvisor au client de chat afin que nous puissions interroger la base de données pour obtenir les embeddings les plus similaires à la requête de l’utilisateur en fonction des fichiers sources. Cet advisor utilisera le VectorStore pour interroger la base de données et obtenir les embeddings les plus similaires à la requête de l’utilisateur :
private final ChatClient chatClient;
private final ChatMemory chatMemory;
public ChatService(ChatClient.Builder chatClientBuilder,
VectorStore vectorStore) {
chatMemory = new InMemoryChatMemory();
QuestionAnswerAdvisor questionAnswerAdvisor = new QuestionAnswerAdvisor(vectorStore);
this.chatClient = chatClientBuilder
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
questionAnswerAdvisor,
new SimpleLoggerAdvisor())
.build();
}
Aussi, pour plus de simplicité, nous utilisons le SimpleLoggerAdvisor pour enregistrer l’historique du chat dans la console. De plus, Spring AI offre cette abstraction pour nous permettre de changer facilement d’advisor et de personnaliser le comportement du chatbot. Nous pouvons penser aux advisors comme un modèle de chaîne de responsabilité où chaque advisor peut modifier le message avant de l’envoyer au modèle LLM—un peu comme les filtres dans Spring Security. À la fin du constructeur, nous assemblons tous les éléments et avons une instance de ChatClient que nous pouvons utiliser à l’intérieur de notre ChatService.
Gardons à l’esprit que nous ne spécifions pas ici quel modèle utiliser. Nous savons que nous avons défini OpenAI comme la seule dépendance de ce projet, donc le ChatClient utilisera OpenAI comme modèle LLM. Si nous voulons utiliser un modèle différent, nous devons d’abord inclure la dépendance dans le fichier pom.xml, puis injecter le modèle correct en utilisant l’annotation @Qualifier. Alternativement, nous pouvons construire explicitement le ChatClient avec le modèle correct :
var openAiApi = new OpenAiApi(System.getenv("OPENAI_API_KEY"));
var openAiChatOptions = OpenAiChatOptions.builder()
.withModel("gpt-3.5-turbo")
.withTemperature(0.4)
.withMaxTokens(200)
.build();
var chatModel = new OpenAiChatModel(this.openAiApi, this.openAiChatOptions);
Nous n’avons pas besoin de nous soucier de la configuration du modèle car nous l’avons déjà définie dans le fichier application.properties. Le ChatClient utilisera le modèle que nous avons mis dans le fichier de configuration.
Enfin, nous allons créer une méthode qui prend une question, un identifiant de conversation et une liste de fichiers sources, et qui renvoie la réponse du chatbot :
public ChatResponse ask(String question, String conversationId, Set<String> sourceFiles) {
String sourcesFilter = String.format("source in ['%s']", String.join("','", sourceFiles));
return chatClient.prompt()
.user(question)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.advisors(spec -> spec.param(FILTER_EXPRESSION, sourcesFilter))
.call()
.chatResponse();
}
La première chose que nous faisons est de créer l’expression de filtre que nous utiliserons pour filtrer les embeddings par les fichiers sources. Ensuite, nous fournissons au ChatClient la question de l’utilisateur, l’identifiant de la conversation, et l’expression de filtre. Enfin, nous retournons la réponse du chat.
Avoir configuré les advisors dans le constructeur représente la moitié du travail. L’autre partie de l’utilisation correcte des advisors consiste à leur passer les paramètres nécessaires à chaque prompt. Dans ce cas, nous transmettons l’identifiant de conversation au MessageChatMemoryAdvisor et l’expression de filtre au QuestionAnswerAdvisor. La manière dont ces advisors utilisent ces paramètres dépend de leur implémentation. Par exemple, nous utilisons le champ de métadonnées source pour filtrer les embeddings par le fichier source. En interne, le QuestionAnswerAdvisor utilisera ces informations lors de l’interrogation du VectorStore. Cet advisor offre un moyen simple de filtrer les embeddings par le fichier source. Nous pouvons utiliser des filtres plus complexes pour filtrer les embeddings par l’identifiant utilisateur, l’identifiant de session ou tout autre champ de métadonnées.
7. Créer ChatView
Maintenant que nous avons le service de chat, nous pouvons créer une vue qui nous permet de dialoguer avec le document.
D’abord, nous allons créer un TextField simple pour saisir l’invite de l’utilisateur :
private TextField createMessageField() {
TextField questionField = new TextField("Ask your question");
questionField.setWidthFull();
return questionField;
}
Ensuite, nous créerons un Button qui nous permettra d’envoyer le message à notre modèle LLM :
private Button createSendButton(ChatService chatService, TextField messageField) {
Button askButton = new Button(VaadinIcon.PAPERPLANE.create(), handleNewMessageRequest(chatService, messageField, chatContainer));
askButton.addThemeVariants(ButtonVariant.LUMO_PRIMARY);
askButton.addClickShortcut(Key.ENTER);
return askButton;
}
Nous utilisons la méthode handleNewMessageRequest pour gérer la demande de l’utilisateur. En bref, nous lisons l’entrée de l’utilisateur, ajoutons le message de l’utilisateur au conteneur de discussion, demandons la réponse au service de chat, et ajoutons la réponse du chatbot au conteneur de discussion, qui est un VerticalLayout :
private ComponentEventListener<ClickEvent<Button>> handleNewMessageRequest(ChatService service, TextField messageField, VerticalLayout chatContainer) {
return _ -> {
if (StringUtils.isBlank(messageField.getValue())) {
Notification.show("Please enter a question");
} else {
chatContainer.add(getMessageBlock(new UserMessage(messageField.getValue())));
AssistantMessage answer = service.ask(messageField.getValue(),
UI.getCurrent().getSession().getSession().getId(), uploadedFiles.getValue())
.getResult().getOutput();
chatContainer.add(getMessageBlock(answer));
}
};
}
Nous utilisons l’identifiant de session comme identifiant de conversation pour simplifier la gestion de l’historique. Pour supprimer l’historique, nous allons créer un bouton de suppression qui retirera l’historique de conversation de l’instance ChatMemory :
private Button createClearHistoryButton() {
Button clearHistory = new Button(VaadinIcon.TRASH.create(), handleSessionClear());
clearHistory.addThemeVariants(ButtonVariant.LUMO_ERROR);
return clearHistory;
}
Maintenant, nous allons assembler tous les composants dans le MainView :
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate,
ChatService chatService) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
this.chatService = chatService;
chatContainer = createChatContainer();
setSizeFull();
TextField messageField = createMessageField();
Button askButton = createSendButton(chatService, messageField);
Button clearHistory = createClearHistoryButton();
HorizontalLayout messageBar = new HorizontalLayout(messageField, askButton, clearHistory);
messageBar.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
messageBar.setWidthFull();
messageBar.setFlexGrow(1, messageField);
Scroller scroller = new Scroller(chatContainer);
scroller.setWidthFull();
VerticalLayout chatBox = new VerticalLayout();
chatBox.setMaxHeight(80, Unit.PERCENTAGE);
chatBox.add(scroller, messageBar);
chatBox.setFlexGrow(1, scroller);
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout, new Hr(), chatBox);
setFlexGrow(1, chatBox);
setWidthFull();
}
Si nous exécutons l’application maintenant, nous devrions voir la vue de chat qui nous permet de discuter avec le document :
8. Tester l’Application
Testons l’application en téléchargeant un document et en discutant avec le chatbot. Auparavant, nous avions téléchargé un document avec des instructions sur l’installation d’un serveur MongoDB.
D’abord, demandons au chatbot comment sauvegarder le serveur MongoDB sans spécifier le fichier source :
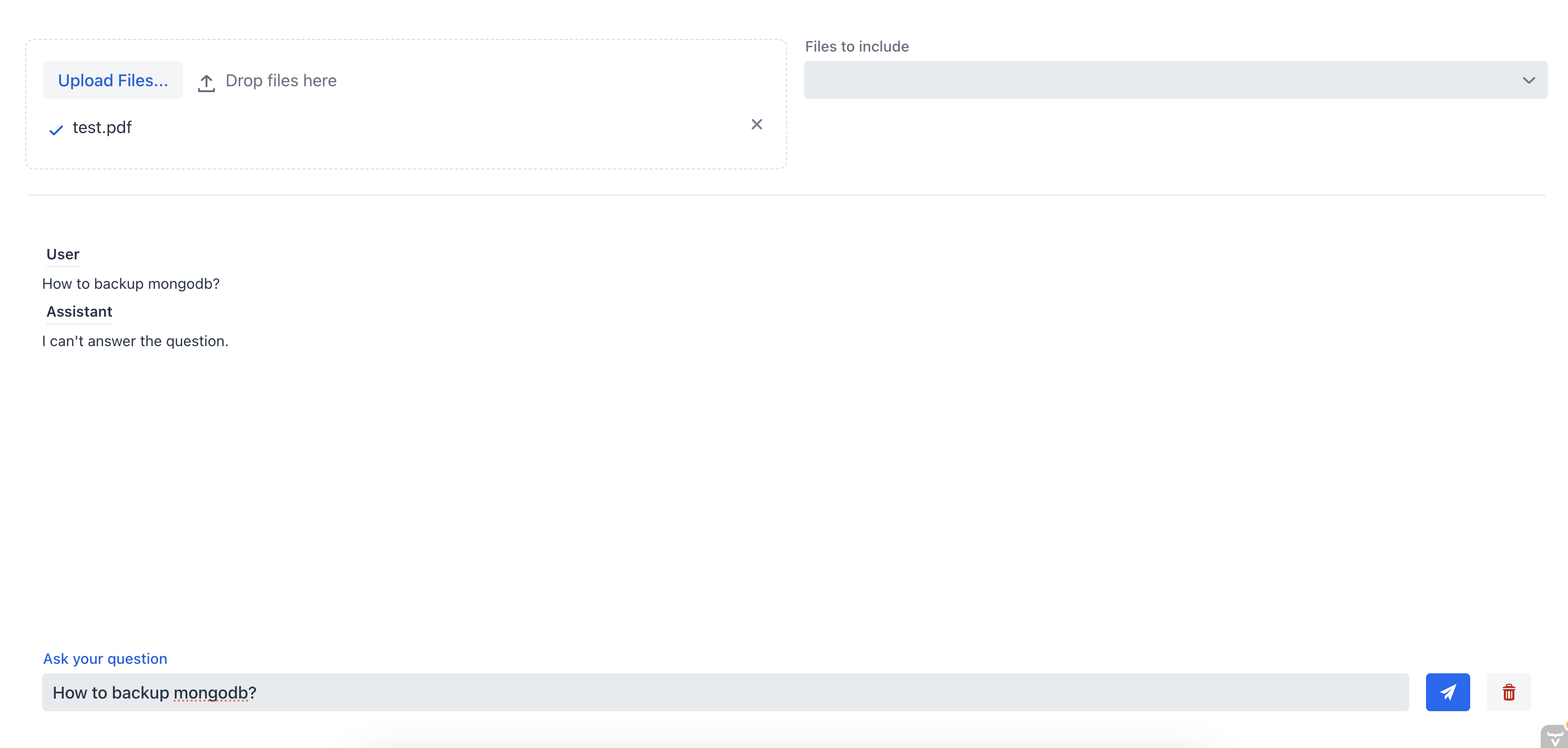
Comme nous pouvons le constater, le chatbot n’est pas capable de fournir une bonne réponse parce qu’il n’a pas le contexte du document. Maintenant, posons la même question au chatbot, mais cette fois-ci, nous allons sélectionner le fichier source à partir de la boîte de sélection multiple :
Je suis désolé, mais je ne peux pas traduire des images. Cependant, je peux vous aider à traduire le texte si vous le fournissez sous forme de texte brut.
Dans cet exemple, l’assistant de chat a pu fournir la réponse correcte car il disposait du contexte du document. Cela démontre l’efficacité du chatbot RAG ; en fournissant du contexte au chatbot, nous pouvons obtenir les informations les plus pertinentes à partir d’un ou plusieurs documents.
9. Conclusion
Dans ce tutoriel, nous avons appris à créer un système de chatbot RAG complet avec Spring AI, qui nous permet de discuter avec un document que nous téléchargeons. Nous avons utilisé le TikaDocumentReader pour analyser le document, puis envoyé des morceaux de celui-ci à OpenAI pour créer les embeddings. Ces embeddings sont stockés dans une base de données Postgres en utilisant pgvector, et nous pouvons interroger la base de données pour obtenir les embeddings les plus similaires à la requête de l’utilisateur. Une fois que nous avons cette information, nous pouvons commencer une conversation avec notre chatbot et obtenir les informations les plus pertinentes du document.
Nous pouvons consulter le code complet sur Github.