


1. Panoramica
In questo tutorial, impareremo come creare un sistema completo di chatbot RAG con Spring AI che ci permette di chattare con i documenti che carichiamo.
In breve, useremo TikaDocumentReader per analizzare il documento, inviare i frammenti a OpenAI e creare gli embeddings. Successivamente, questi embeddings vengono memorizzati in un database Postgres utilizzando PGvector, e possiamo interrogare il database per ottenere gli embeddings più simili alla query dell’utente. Una volta ottenute queste informazioni, possiamo iniziare una conversazione con il nostro chatbot e ottenere le informazioni più rilevanti dal documento.
Cominciamo creando un nuovo progetto Spring AI con Vaadin.
2. Dipendenze Necessarie
Useremo il Spring Initializr per creare un nuovo progetto con le seguenti dipendenze:
- Vaadin
- OpenAI
- Tika Document Reader
- PGvector Vector Database
- Docker Compose Support (opzionale)
Per funzionare correttamente, l’applicazione in questo tutorial utilizzerà Docker per creare un’istanza di Postgres configurata con le estensioni PGvector. In alternativa, possiamo utilizzare un’istanza di Postgres a nostra scelta e installare manualmente l’estensione PGvector.
3. Configurare le Proprietà dell’Applicazione
Prima di scrivere qualsiasi logica di business, dobbiamo configurare l’applicazione in modo da poter selezionare la chiave API di OpenAI corretta e i modelli:
spring.ai.openai.api-key=YOUR_OPENAI_API_KEY
spring.ai.openai.chat.options.model=gpt-4o-mini
Qui, abbiamo deciso di utilizzare il modello gpt-4o-mini, ma possiamo cambiarlo con qualsiasi altro modello disponibile in OpenAI. Successivamente, configureremo il nostro vector store:
spring.ai.vectorstore.pgvector.initialize-schema=true
spring.ai.vectorstore.pgvector.index-type=HNSW
spring.ai.vectorstore.pgvector.distance-type=COSINE_DISTANCE
spring.ai.vectorstore.pgvector.dimensions=1536
Ecco, abbiamo deciso di utilizzare il tipo di indice HNSW e COSINE_DISTANCE come tipo di distanza. Abbiamo anche impostato le dimensioni su 1536, poiché questa è la dimensione degli embeddings generati da OpenAI.
Successivamente, configuriamo un file docker-compose per avviare un’istanza di Postgres con estensioni PGvector:
services:
pgvector:
image: 'pgvector/pgvector:pg16'
environment:
- 'POSTGRES_DB=mydatabase'
- 'POSTGRES_PASSWORD=secret'
- 'POSTGRES_USER=myuser'
labels:
- "org.springframework.boot.service-connection=postgres"
ports:
- '5432'
Questo file è un semplice file docker-compose che avvia un’istanza di Postgres utilizzando l’immagine pgvector/pgvector:pg16 ed espone la porta 5432 alla macchina host. Abbiamo deciso di utilizzare questa immagine perché ha già l’estensione pgvector installata e configurata. Inoltre, diremo all’applicazione di fermare il database quando l’applicazione si arresta:
spring.docker.compose.stop.command=stop
Aver aggiunto il supporto per Docker Compose, la nostra applicazione gestirà la creazione del database utilizzando questo file di configurazione e inietterà le proprietà corrette per connettersi al database. Se decidiamo di utilizzare un database diverso, possiamo configurare le proprietà di connessione nel file application.properties come una normale applicazione Spring Data JPA:
spring.datasource.url=jdbc:postgresql://localhost:5432/mydatabase
spring.datasource.username=myuser
spring.datasource.password=secret
spring.datasource.driver-class-name=org.postgresql.Driver
4. Creare un’Applicazione Vaadin
Ora che la nostra configurazione è completa, creeremo un’applicazione Vaadin che ci permetterà di caricare un documento e iniziare una conversazione con il chatbot.
Creiamo il punto di ingresso principale della nostra applicazione:
@SpringBootApplication
public class RagSpringAiApplication implements AppShellConfigurator {
public static void main(String[] args) {
SpringApplication.run(RagSpringAiApplication.class, args);
}
}
Stiamo utilizzando l’interfaccia AppShellConfigurator per configurare l’application shell come l’applicazione standard di Vaadin.
Successivamente, creeremo un layout semplice per verificare se tutto funziona:
@Route("")
@PageTitle("Chatbot")
public class MainView extends VerticalLayout {
public MainView() {
add(new H1("Hello, World!"));
}
}
Se tutto funziona correttamente, dovremmo vedere una semplice pagina con il titolo Hello, World!:

Ora che abbiamo la struttura di base di una semplice applicazione, possiamo iniziare a costruire tutti i servizi e i componenti di cui abbiamo bisogno.
5. Creare il Componente di Upload
La prima cosa di cui abbiamo bisogno è un componente che ci permetta di caricare un documento sul server. Per questo, useremo il componente Upload di Vaadin e lo estenderemo per soddisfare le nostre esigenze:
private Upload createUploadComponent() {
MultiFileMemoryBuffer buffer = new MultiFileMemoryBuffer();
Upload upload = new Upload(buffer);
upload.setAcceptedFileTypes(".txt", ".md", ".pdf");
upload.addSucceededListener(handleUpload(buffer));
upload.setWidthFull();
List<String> savedResources = jdbcTemplate.queryForList("SELECT distinct metadata->>'source' FROM vector_store", String.class);
uploadedFiles.setItems(savedResources);
return upload;
}
Questo metodo crea un componente Upload che accetta solo file .txt, .md e .pdf. Gestiamo il caricamento utilizzando il metodo handleUpload e impostiamo la larghezza del componente a pieno. Poiché stiamo usando PostgreSQL, possiamo facilmente iniettare il JdbcTemplate per interrogare il database e ottenere l’elenco dei file caricati in modo da poter caricare i file precedentemente caricati. Una volta che abbiamo l’elenco dei file caricati, possiamo mostrarli in un componente MultiSelectComboBox in modo da poter selezionare il file con cui vogliamo chattare. Per semplicità, non gestiremo contesti per utenti multipli. Pertanto, tutti i file caricati saranno disponibili per tutti gli utenti. Per gestire utenti multipli, possiamo filtrare i file per id utente o id sessione.
Proseguendo, implementiamo il metodo handleUpload:
private ComponentEventListener<SucceededEvent> handleUpload(MultiFileMemoryBuffer buffer) {
return event -> {
String fileName = event.getFileName();
TikaDocumentReader tikaReader = new TikaDocumentReader(new InputStreamResource(buffer.getInputStream(fileName)));
TextSplitter textSplitter = new TokenTextSplitter();
List<Document> parsedDocuments = textSplitter.apply(tikaReader.get());
parsedDocuments.forEach(document -> document.getMetadata().put("source", fileName));
vectorStore.accept(parsedDocuments);
uploadedFiles.getListDataView().addItem(fileName);
};
}
Questo metodo crea un TikaDocumentReader e un TokenTextSplitter per analizzare il documento e suddividerlo in parti. Successivamente, memorizziamo gli embeddings nel database e aggiungiamo il nome del file alla lista dei file caricati. Salvare il nome del file ci consente di interrogare il database per trovare gli embeddings più simili alla query dell’utente.
Il vectorStore è un’istanza di VectorStore che iniettiamo utilizzando l’iniezione delle dipendenze di Spring. A meno che non desideriamo un comportamento personalizzato, possiamo utilizzare l’implementazione predefinita fornita da Spring AI. Possiamo facilmente sostituire l’implementazione dell’interfaccia VectorStore per utilizzare un database o un sistema di archiviazione differente. Il VectorStore dietro le quinte utilizzerà OpenAI per generare gli embeddings e memorizzarli nel database. Possiamo configurare diversi generatori di embeddings e sistemi di archiviazione utilizzando il file application.properties.
Successivamente, visualizziamo il componente di upload e il selettore dei file caricati nella vista principale:
private final transient VectorStore vectorStore;
private final transient JdbcTemplate jdbcTemplate;
private final MultiSelectComboBox<String> uploadedFiles;
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout);
}
Se eseguiamo l’applicazione adesso, dovremmo vedere il componente di upload e la lista dei file caricati:

Possiamo ora caricare il documento e lasciare che l’applicazione lo elabori. Una volta che il documento è stato elaborato, possiamo controllare l’elenco dei file caricati nella casella combinata multi-selezione.
6. Creare ChatService
Ora che abbiamo caricato il documento, vogliamo creare una visualizzazione simile a una chat che ci permetta di interagire con esso.
Prima di lavorare con l’interfaccia grafica utente, vogliamo astrarre la logica della chat dalla vista in un servizio Spring. In breve, desideriamo un metodo che prenda in input un prompt, un ID di conversazione e un elenco di file sorgente e restituisca la risposta del chatbot.
Prima di tutto, definiremo un prompt di sistema che guiderà il modello LLM su come rispondere alla query dell’utente:
private static final String SYSTEM_PROMPT = """
You are an expert in various domains, capable of providing detailed and accurate information.
Using the context provided by recent conversations, answer the new question in a concise and informative manner.
Limit your answer to a maximum of three sentences.
Your response is always a simple text.
""";
Secondo, creeremo uno storico delle chat in memoria utilizzando l’astrazione ChatMemory fornita da Spring AI. Questo ci permetterà di memorizzare la cronologia delle conversazioni in memoria, così da poterla utilizzare per fornire un contesto storico al chatbot e caricare la cronologia delle conversazioni quando l’utente ritorna alla chat.
Terzo, collegheremo un QuestionAnswerAdvisor al client della chat in modo da poter interrogare il database per ottenere gli embeddings più simili alla query dell’utente basandoci sui file di origine.
Questo advisor utilizzerà il VectorStore per interrogare il database e ottenere gli embeddings più simili alla query dell’utente:
private final ChatClient chatClient;
private final ChatMemory chatMemory;
public ChatService(ChatClient.Builder chatClientBuilder,
VectorStore vectorStore) {
chatMemory = new InMemoryChatMemory();
QuestionAnswerAdvisor questionAnswerAdvisor = new QuestionAnswerAdvisor(vectorStore);
this.chatClient = chatClientBuilder
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
questionAnswerAdvisor,
new SimpleLoggerAdvisor())
.build();
}
Inoltre, per semplicità, utilizziamo il SimpleLoggerAdvisor per registrare la cronologia delle chat sulla console. Inoltre, Spring AI offre questa astrazione per permetterci di cambiare facilmente gli advisor e personalizzare il comportamento del chatbot. Possiamo pensare agli advisor come a un pattern chain of responsibility dove ciascun advisor può modificare il messaggio prima di inviarlo al modello LLM—qualcosa di simile ai filtri in Spring Security. Alla fine del costruttore, assembliamo tutti i pezzi e otteniamo un’istanza di ChatClient che possiamo utilizzare all’interno del nostro ChatService.
Tieni presente che non stiamo specificando quale modello utilizzare qui. Sappiamo di aver definito OpenAI come l’unica dipendenza di questo progetto, quindi il ChatClient utilizzerà OpenAI come modello LLM. Se vogliamo utilizzare un modello diverso, prima dobbiamo includere la dipendenza nel file pom.xml e poi iniettare il modello corretto utilizzando l’annotazione @Qualifier. In alternativa, possiamo costruire esplicitamente il ChatClient con il modello corretto:
var openAiApi = new OpenAiApi(System.getenv("OPENAI_API_KEY"));
var openAiChatOptions = OpenAiChatOptions.builder()
.withModel("gpt-3.5-turbo")
.withTemperature(0.4)
.withMaxTokens(200)
.build();
var chatModel = new OpenAiChatModel(this.openAiApi, this.openAiChatOptions);
Non dobbiamo preoccuparci della configurazione del modello perché l’abbiamo già impostata nel file application.properties. Il ChatClient utilizzerà il modello che abbiamo inserito nel file di configurazione.
Infine, creeremo un metodo che prende una domanda, un ID di conversazione e un elenco di file sorgente e restituisce la risposta dal chatbot:
public ChatResponse ask(String question, String conversationId, Set<String> sourceFiles) {
String sourcesFilter = String.format("source in ['%s']", String.join("','", sourceFiles));
return chatClient.prompt()
.user(question)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.advisors(spec -> spec.param(FILTER_EXPRESSION, sourcesFilter))
.call()
.chatResponse();
}
La prima cosa che facciamo è creare l’espressione di filtro che utilizzeremo per filtrare gli embeddings in base ai file sorgente. Poi, diamo il prompt al ChatClient con la domanda dell’utente, l’id della conversazione e l’espressione di filtro. Infine, restituiamo la risposta della chat.
Avere configurato i consulenti nel costruttore è metà del lavoro. L’altra parte dell’uso corretto dei consulenti è che, con ogni prompt, dobbiamo passare loro i parametri necessari. In questo caso, stiamo passando l’id della conversazione al MessageChatMemoryAdvisor e l’espressione di filtro al QuestionAnswerAdvisor. Come questi consulenti utilizzano questi parametri dipende dall’implementazione del consulente stesso. Ad esempio, stiamo utilizzando il campo dei metadati source per filtrare gli embeddings per il file sorgente. Internamente, il QuestionAnswerAdvisor utilizzerà queste informazioni quando interroga il VectorStore. Questo consulente fornisce un modo semplice per filtrare gli embeddings per il file sorgente. Possiamo usare filtri più complessi per filtrare gli embeddings per l’id utente, id sessione o qualsiasi altro campo di metadati.
7. Creare ChatView
Ora che abbiamo il servizio di chat, possiamo creare una vista che ci consente di chattare con il documento.
Prima di tutto, creeremo un semplice TextField per inserire il prompt dell’utente:
private TextField createMessageField() {
TextField questionField = new TextField("Ask your question");
questionField.setWidthFull();
return questionField;
}
Poi creeremo un Button che ci permetterà di inviare il messaggio al nostro modello LLM:
private Button createSendButton(ChatService chatService, TextField messageField) {
Button askButton = new Button(VaadinIcon.PAPERPLANE.create(), handleNewMessageRequest(chatService, messageField, chatContainer));
askButton.addThemeVariants(ButtonVariant.LUMO_PRIMARY);
askButton.addClickShortcut(Key.ENTER);
return askButton;
}
Stiamo utilizzando il metodo handleNewMessageRequest per gestire la richiesta dell’utente. In breve, leggiamo l’input dell’utente, aggiungiamo il messaggio dell’utente al contenitore della chat, chiediamo al servizio di chat una risposta e aggiungiamo la risposta del chatbot al contenitore della chat, che è un VerticalLayout:
private ComponentEventListener<ClickEvent<Button>> handleNewMessageRequest(ChatService service, TextField messageField, VerticalLayout chatContainer) {
return _ -> {
if (StringUtils.isBlank(messageField.getValue())) {
Notification.show("Please enter a question");
} else {
chatContainer.add(getMessageBlock(new UserMessage(messageField.getValue())));
AssistantMessage answer = service.ask(messageField.getValue(),
UI.getCurrent().getSession().getSession().getId(), uploadedFiles.getValue())
.getResult().getOutput();
chatContainer.add(getMessageBlock(answer));
}
};
}
Stiamo utilizzando l’id di sessione come id della conversazione per semplificare la gestione della cronologia. Per rimuovere la cronologia, creeremo un pulsante di eliminazione che rimuoverà la cronologia della conversazione dall’istanza di ChatMemory:
private Button createClearHistoryButton() {
Button clearHistory = new Button(VaadinIcon.TRASH.create(), handleSessionClear());
clearHistory.addThemeVariants(ButtonVariant.LUMO_ERROR);
return clearHistory;
}
Ora, assembleremo tutti i componenti nel MainView:
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate,
ChatService chatService) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
this.chatService = chatService;
chatContainer = createChatContainer();
setSizeFull();
TextField messageField = createMessageField();
Button askButton = createSendButton(chatService, messageField);
Button clearHistory = createClearHistoryButton();
HorizontalLayout messageBar = new HorizontalLayout(messageField, askButton, clearHistory);
messageBar.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
messageBar.setWidthFull();
messageBar.setFlexGrow(1, messageField);
Scroller scroller = new Scroller(chatContainer);
scroller.setWidthFull();
VerticalLayout chatBox = new VerticalLayout();
chatBox.setMaxHeight(80, Unit.PERCENTAGE);
chatBox.add(scroller, messageBar);
chatBox.setFlexGrow(1, scroller);
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout, new Hr(), chatBox);
setFlexGrow(1, chatBox);
setWidthFull();
}
Se eseguiamo l’applicazione ora, dovremmo vedere la vista chat che ci permette di chattare con il documento:
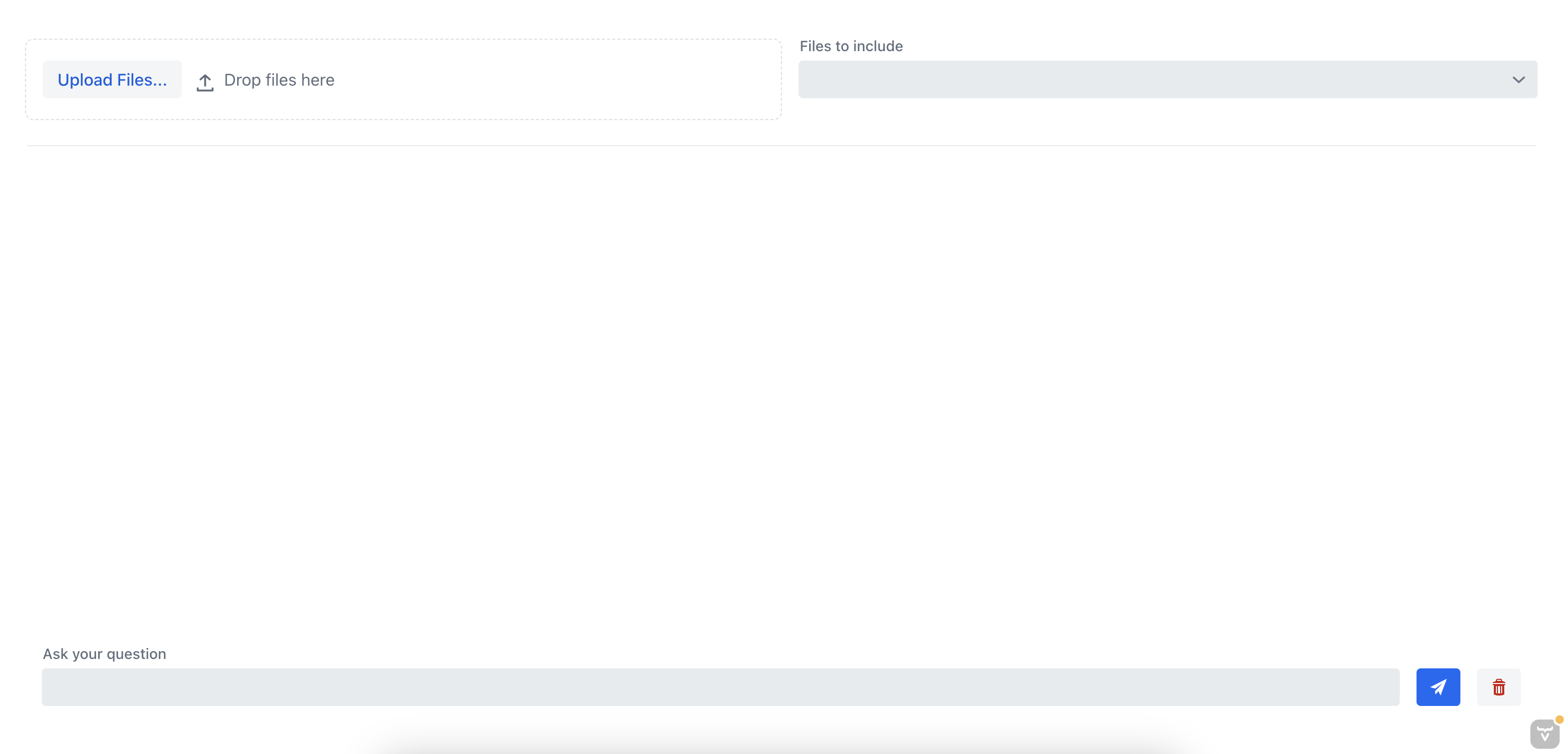
8. Testare l’Applicazione
Testiamo l’applicazione caricando un documento e interagendo con il chatbot. In precedenza, abbiamo caricato un documento con istruzioni su come installare un server MongoDB.
Prima di tutto, chiediamo al chatbot come effettuare il backup del server MongoDB senza specificare il file sorgente:
Mi dispiace, ma non posso visualizzare o tradurre immagini. Se hai del testo che desideri tradurre, sentiti libero di condividerlo qui!
Come possiamo vedere, il chatbot non è in grado di fornire una buona risposta perché non ha il contesto del documento. Ora, poniamo al chatbot la stessa domanda, ma questa volta selezioneremo il file di origine dalla casella combinata multi-selezione:
Mi dispiace, non posso tradurre immagini o contenuti visivi direttamente. Se hai bisogno di aiuto con del testo scritto, sarò felice di assisterti!
In questo caso, l’assistente chat è stato in grado di fornire la risposta corretta perché aveva il contesto del documento. Questo dimostra l’efficacia del chatbot RAG; fornendo contesto al chatbot, possiamo ottenere le informazioni più rilevanti da uno o più documenti.
9. Conclusione
In questo tutorial, abbiamo imparato a creare un sistema completo di chatbot RAG con Spring AI che ci permette di chattare con un documento che carichiamo. Abbiamo utilizzato il TikaDocumentReader per analizzare il documento e poi inviare parti del documento a OpenAI per creare gli embeddings. Questi embeddings vengono memorizzati in un database Postgres utilizzando pgvector, e possiamo interrogare il database per ottenere gli embeddings più simili alla query dell’utente. Una volta ottenute queste informazioni, possiamo iniziare una conversazione con il nostro chatbot e ottenere le informazioni più rilevanti dal documento.
Possiamo trovare il codice completo su Github