


1. Обзор
В этом руководстве мы узнаем, как создать полноценную систему RAG chatbot с помощью Spring AI, которая позволит нам вести диалог с загруженными документами.
Вкратце, мы будем использовать TikaDocumentReader для парсинга документа, отправлять chunks в OpenAI и создавать embeddings.
Затем эти embeddings сохраняются в базе данных Postgres с помощью PGvector, и мы можем запрашивать базу, чтобы получить embeddings, наиболее похожие на user query.
Как только у нас появится эта информация, мы сможем начать разговор с нашим chatbot и получить наиболее релевантную информацию из документа.
Давайте начнём с создания нового проекта Spring AI с Vaadin.
2. Необходимые Dependencies
Мы используем Spring Initializr, чтобы создать новый проект со следующими dependencies:
- Vaadin
- OpenAI
- Tika Document Reader
- PGvector Vector Database
- Поддержка Docker Compose (необязательно)
Чтобы приложение в этом руководстве работало корректно, мы будем использовать docker для создания экземпляра Postgres, сконфигурированного с расширениями PGvector. В противном случае мы можем использовать любой экземпляр Postgres по нашему выбору и установить расширение PGvector вручную.
3. Настройте Application Properties
Прежде чем писать любую business logic, нам нужно настроить приложение, чтобы мы могли выбрать правильный OpenAI API key и models:
spring.ai.openai.api-key=YOUR_OPENAI_API_KEY
spring.ai.openai.chat.options.model=gpt-4o-mini
Здесь мы решили использовать модель gpt-4o-mini, но можем заменить её на любую другую доступную модель в OpenAI.
Далее настроим наш vector store:
spring.ai.vectorstore.pgvector.initialize-schema=true
spring.ai.vectorstore.pgvector.index-type=HNSW
spring.ai.vectorstore.pgvector.distance-type=COSINE_DISTANCE
spring.ai.vectorstore.pgvector.dimensions=1536
Здесь мы решили использовать тип индекса HNSW и в качестве типа расстояния — COSINE_DISTANCE. Мы также установили размерность 1536, поскольку это размерность эмбеддингов, генерируемых OpenAI.
Далее мы настраиваем файл docker-compose, чтобы запустить экземпляр Postgres с PGvector extensions:
services:
pgvector:
image: 'pgvector/pgvector:pg16'
environment:
- 'POSTGRES_DB=mydatabase'
- 'POSTGRES_PASSWORD=secret'
- 'POSTGRES_USER=myuser'
labels:
- "org.springframework.boot.service-connection=postgres"
ports:
- '5432'
Этот файл — простой файл docker-compose, который запускает экземпляр Postgres с образом pgvector/pgvector:pg16 и пробрасывает порт 5432 на хост-машину. Мы решили использовать этот образ, потому что в нём уже установлен и настроен pgvector extension. Также мы настроим приложение так, чтобы оно останавливало базу данных при остановке приложения:
spring.docker.compose.stop.command=stop
Добавив поддержку Docker Compose, наше приложение будет создавать базу данных с помощью этого конфигурационного файла и подставлять корректные свойства для подключения к базе данных. Если мы решим использовать другую базу данных, мы можем настроить свойства подключения в файле application.properties, как в обычном приложении на Spring Data JPA:
spring.datasource.url=jdbc:postgresql://localhost:5432/mydatabase
spring.datasource.username=myuser
spring.datasource.password=secret
spring.datasource.driver-class-name=org.postgresql.Driver
4. Создаём Vaadin Application
Теперь, когда наша конфигурация завершена, мы создадим Vaadin Application, который позволит нам загрузить документ и начать разговор с chatbot.
Давайте создадим основную точку входа нашего приложения:
@SpringBootApplication
public class RagSpringAiApplication implements AppShellConfigurator {
public static void main(String[] args) {
SpringApplication.run(RagSpringAiApplication.class, args);
}
}
Мы используем интерфейс AppShellConfigurator, чтобы настроить application shell в качестве стандартного приложения Vaadin.
Далее мы создадим простой макет, чтобы проверить, что всё работает:
@Route("")
@PageTitle("Chatbot")
public class MainView extends VerticalLayout {
public MainView() {
add(new H1("Hello, World!"));
}
}
Если всё работает правильно, мы должны увидеть простую страницу с заголовком Hello, World!:

Теперь, когда у нас есть simple application’s backbone, мы можем начать создавать все services и components, которые нам нужны.
5. Создайте Upload Component
Первое, что нам нужно — это компонент, который позволяет загрузить документ на сервер. Для этого мы будем использовать компонент Upload из Vaadin и расширим его, чтобы он соответствовал нашим требованиям:
private Upload createUploadComponent() {
MultiFileMemoryBuffer buffer = new MultiFileMemoryBuffer();
Upload upload = new Upload(buffer);
upload.setAcceptedFileTypes(".txt", ".md", ".pdf");
upload.addSucceededListener(handleUpload(buffer));
upload.setWidthFull();
List<String> savedResources = jdbcTemplate.queryForList("SELECT distinct metadata->>'source' FROM vector_store", String.class);
uploadedFiles.setItems(savedResources);
return upload;
}
Этот метод создаёт компонент Upload, который принимает только файлы .txt, .md и .pdf. Мы обрабатываем загрузку с помощью метода handleUpload и устанавливаем ширину компонента на full.
Поскольку мы используем PostgreSQL, мы можем легко внедрить JdbcTemplate, чтобы выполнить запрос к базе данных и получить список загруженных файлов, чтобы подгрузить ранее загруженные файлы. Как только у нас будет список загруженных файлов, мы можем отобразить их в компоненте MultiSelectComboBox, чтобы выбрать файл, с которым мы хотим общаться. Для простоты мы не будем обрабатывать контексты для нескольких пользователей. Поэтому все загруженные файлы будут доступны всем пользователям. Чтобы поддержать несколько пользователей, мы можем фильтровать файлы по user id или session id.
Двигаясь дальше, давайте реализуем метод handleUpload:
private ComponentEventListener<SucceededEvent> handleUpload(MultiFileMemoryBuffer buffer) {
return event -> {
String fileName = event.getFileName();
TikaDocumentReader tikaReader = new TikaDocumentReader(new InputStreamResource(buffer.getInputStream(fileName)));
TextSplitter textSplitter = new TokenTextSplitter();
List<Document> parsedDocuments = textSplitter.apply(tikaReader.get());
parsedDocuments.forEach(document -> document.getMetadata().put("source", fileName));
vectorStore.accept(parsedDocuments);
uploadedFiles.getListDataView().addItem(fileName);
};
}
Этот метод создаёт TikaDocumentReader и TokenTextSplitter, чтобы распарсить документ и разбить его на фрагменты. Затем мы сохраняем embeddings в database и добавляем file name в список uploaded files. Сохранение file name позволяет нам в database искать наиболее похожие embeddings по user query.
vectorStore — это экземпляр VectorStore, который мы внедряем с помощью dependency injection в Spring. Если мы не хотим custom behavior, можем использовать default implementation, предоставляемую Spring AI. Мы легко можем поменять implementation интерфейса VectorStore, чтобы использовать другую database или storage system. Под капотом VectorStore использует OpenAI для генерации embeddings и сохранения их в database. Мы можем настроить разные embedding generators и storage systems через файл application.properties.
Далее давайте отобразим upload component и selector of the uploaded files в main view:
private final transient VectorStore vectorStore;
private final transient JdbcTemplate jdbcTemplate;
private final MultiSelectComboBox<String> uploadedFiles;
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout);
}
Если мы запустим приложение сейчас, мы должны увидеть upload component и список uploaded files:

Теперь мы можем upload документ и позволить приложению обработать его. После того как документ будет обработан, мы можем проверить список uploaded files в multi-select combo box.
6. Создаём ChatService
Теперь, когда мы загрузили документ, давайте создадим chat-like view, которая позволит нам взаимодействовать с ним.
Прежде чем работать с graphical user interface, мы хотим абстрагировать chat logic от view в spring service. Вкратце, мы хотим метод, который принимает prompt, conversation id и список source files и возвращает chatbot’s response.
Сначала мы определим system prompt, который будет направлять LLM model при ответе на user query:
private static final String SYSTEM_PROMPT = """
You are an expert in various domains, capable of providing detailed and accurate information.
Using the context provided by recent conversations, answer the new question in a concise and informative manner.
Limit your answer to a maximum of three sentences.
Your response is always a simple text.
""";
Во-вторых, мы создадим in-memory chat history с помощью абстракции ChatMemory, предоставляемой Spring AI. Это позволит нам сохранять conversation history в памяти, чтобы мы могли использовать её для предоставления исторического контекста chatbot и загружать conversation history, когда пользователь возвращается в чат.
В-третьих, мы подключим QuestionAnswerAdvisor к chat client, чтобы иметь возможность запрашивать в базе данных наиболее похожие embeddings для запроса пользователя на основе исходных файлов.
Этот advisor будет использовать VectorStore для запроса базы данных и получения наиболее похожих embeddings на запрос пользователя:
private final ChatClient chatClient;
private final ChatMemory chatMemory;
public ChatService(ChatClient.Builder chatClientBuilder,
VectorStore vectorStore) {
chatMemory = new InMemoryChatMemory();
QuestionAnswerAdvisor questionAnswerAdvisor = new QuestionAnswerAdvisor(vectorStore);
this.chatClient = chatClientBuilder
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
questionAnswerAdvisor,
new SimpleLoggerAdvisor())
.build();
}
Также, для простоты, мы используем SimpleLoggerAdvisor, чтобы логировать историю чата в консоль.
Кроме того, Spring AI предоставляет эту абстракцию, чтобы мы могли легко заменять advisors и настраивать поведение chatbot. Мы можем рассматривать advisors как chain of responsibility pattern, где каждый advisor может изменять сообщение перед отправкой в LLM model — нечто вроде filters в Spring Security.
В конце конструктора мы собираем все части и получаем экземпляр ChatClient, который можем использовать внутри нашего ChatService.
Имейте в виду, что здесь мы не указываем, какую модель использовать. Мы знаем, что задали OpenAI как единственную зависимость этого проекта, поэтому ChatClient будет использовать OpenAI как LLM-модель. Если мы хотим использовать другую модель, сначала нужно добавить зависимость в файл pom.xml, а затем внедрить правильную модель с помощью аннотации @Qualifier. В качестве альтернативы, мы можем явно создать ChatClient с нужной моделью:
var openAiApi = new OpenAiApi(System.getenv("OPENAI_API_KEY"));
var openAiChatOptions = OpenAiChatOptions.builder()
.withModel("gpt-3.5-turbo")
.withTemperature(0.4)
.withMaxTokens(200)
.build();
var chatModel = new OpenAiChatModel(this.openAiApi, this.openAiChatOptions);
Нам не нужно беспокоиться о конфигурации модели, потому что мы уже задали её в файле application.properties. ChatClient будет использовать модель, которую мы указали в файле конфигурации.
Наконец, мы создадим метод, который принимает question, conversation id и list of source files, и возвращает response от chatbot:
public ChatResponse ask(String question, String conversationId, Set<String> sourceFiles) {
String sourcesFilter = String.format("source in ['%s']", String.join("','", sourceFiles));
return chatClient.prompt()
.user(question)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.advisors(spec -> spec.param(FILTER_EXPRESSION, sourcesFilter))
.call()
.chatResponse();
}
Первое, что мы делаем — создаём filter expression, который будем использовать для фильтрации embeddings по source files. Затем мы prompt the ChatClient с user question, conversation id и filter expression. Наконец, мы возвращаем chat response.
Настройка advisors в конструкторе — это только половина работы. Другая часть правильного использования advisors заключается в том, что с каждым prompt мы должны передавать им необходимые параметры. В данном случае мы передаём conversation id в MessageChatMemoryAdvisor, а filter expression — в QuestionAnswerAdvisor. То, как эти advisors используют переданные параметры, зависит от реализации конкретного advisor. Например, мы используем поле метаданных source, чтобы фильтровать embeddings по source file. Внутри QuestionAnswerAdvisor эта информация будет учтена при запросе к VectorStore. Этот advisor даёт простой способ фильтрации embeddings по source file, но мы также можем применять более сложные фильтры — например, по user id, session id или любому другому metadata field.
7. Создание ChatView
Теперь, когда у нас есть chat service, давайте создадим view, который позволит нам chat with the document.
Сначала мы создадим простой TextField для ввода запроса пользователя:
private TextField createMessageField() {
TextField questionField = new TextField("Ask your question");
questionField.setWidthFull();
return questionField;
}
Затем мы создадим Button, который позволит нам отправить сообщение нашей модели LLM:
private Button createSendButton(ChatService chatService, TextField messageField) {
Button askButton = new Button(VaadinIcon.PAPERPLANE.create(), handleNewMessageRequest(chatService, messageField, chatContainer));
askButton.addThemeVariants(ButtonVariant.LUMO_PRIMARY);
askButton.addClickShortcut(Key.ENTER);
return askButton;
}
Мы используем метод handleNewMessageRequest для обработки запроса пользователя. Проще говоря, мы читаем ввод пользователя, добавляем сообщение пользователя в chat container, запрашиваем ответ у chat service и добавляем ответ чат-бота в chat container, который является VerticalLayout:
private ComponentEventListener<ClickEvent<Button>> handleNewMessageRequest(ChatService service, TextField messageField, VerticalLayout chatContainer) {
return _ -> {
if (StringUtils.isBlank(messageField.getValue())) {
Notification.show("Please enter a question");
} else {
chatContainer.add(getMessageBlock(new UserMessage(messageField.getValue())));
AssistantMessage answer = service.ask(messageField.getValue(),
UI.getCurrent().getSession().getSession().getId(), uploadedFiles.getValue())
.getResult().getOutput();
chatContainer.add(getMessageBlock(answer));
}
};
}
Мы используем session id в качестве conversation id, чтобы упростить управление историей. Чтобы удалить историю, мы создадим кнопку удаления, которая удалит историю разговора из экземпляра ChatMemory:
private Button createClearHistoryButton() {
Button clearHistory = new Button(VaadinIcon.TRASH.create(), handleSessionClear());
clearHistory.addThemeVariants(ButtonVariant.LUMO_ERROR);
return clearHistory;
}
Теперь мы соберём все компоненты в MainView:
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate,
ChatService chatService) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
this.chatService = chatService;
chatContainer = createChatContainer();
setSizeFull();
TextField messageField = createMessageField();
Button askButton = createSendButton(chatService, messageField);
Button clearHistory = createClearHistoryButton();
HorizontalLayout messageBar = new HorizontalLayout(messageField, askButton, clearHistory);
messageBar.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
messageBar.setWidthFull();
messageBar.setFlexGrow(1, messageField);
Scroller scroller = new Scroller(chatContainer);
scroller.setWidthFull();
VerticalLayout chatBox = new VerticalLayout();
chatBox.setMaxHeight(80, Unit.PERCENTAGE);
chatBox.add(scroller, messageBar);
chatBox.setFlexGrow(1, scroller);
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout, new Hr(), chatBox);
setFlexGrow(1, chatBox);
setWidthFull();
}
Если мы запустим приложение сейчас, мы должны увидеть chat view, который позволяет нам общаться с документом:
8. Тестирование приложения
Давайте протестируем приложение, загрузив документ и пообщавшись с chatbot. Ранее мы загрузили документ с инструкциями по установке MongoDB server.
Сначала давайте спросим чат-бота, как сделать backup сервера MongoDB, не указывая исходный файл:
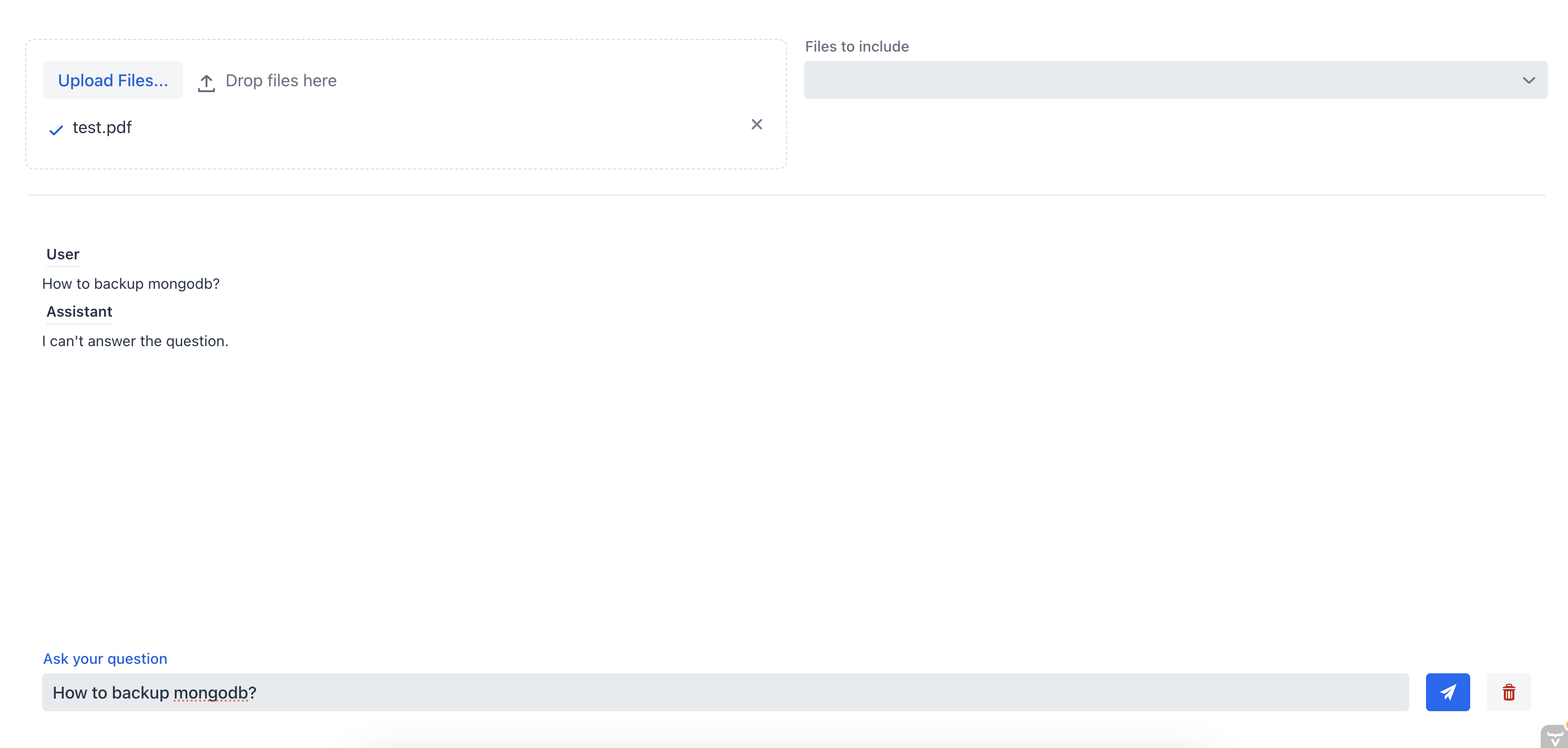
Как мы видим, chatbot не может дать хороший ответ, потому что у него нет контекста документа. Теперь давайте зададим chatbot тот же вопрос, но на этот раз мы выберем source file из multi-select combo box:
Я не вижу содержимого изображения — у меня нет доступа к файлам по ссылкам. Пожалуйста, либо:
- Вставьте сюда текст, который нужно перевести, или
- Прикрепите сам файл изображения (если интерфейс поддерживает загрузку), и я извлеку текст и переведу его.
Если в тексте есть Markdown-разметка, код или технические термины, пожалуйста, оставьте их как есть — я сохраню форматирование и оставлю технические термины на английском.
В этом случае chat assistant смог предоставить правильный ответ, потому что имел доступ к контексту документа. Это демонстрирует эффективность RAG chatbot: предоставляя контекст chatbot, мы можем получить наиболее релевантную информацию из одного или нескольких документов.
9. Заключение
В этом руководстве мы научились создавать полноценную RAG chatbot system с Spring AI, которая позволяет нам общаться с документом, который мы загружаем. Мы использовали TikaDocumentReader для парсинга документа, а затем отправляли чанки документа в OpenAI для создания embeddings. Эти embeddings сохраняются в Postgres database с помощью pgvector, и мы можем query the database, чтобы получить embeddings, наиболее похожие на user query. Как только у нас появляется эта информация, мы можем начать conversation с нашим chatbot и получить наиболее релевантную информацию из документа.
Мы можем посмотреть полный code on Github