


1. 概述
在本教程中,我们将学习如何使用 Spring AI 创建一个完整的 RAG 聊天机器人系统,使我们能够与我们上传的文档进行对话。
简而言之,我们将使用 TikaDocumentReader 来解析文档,将文档分块发送到 OpenAI,并创建嵌入。然后,这些嵌入将使用 PGvector 存储在 Postgres 数据库中,我们可以查询数据库以获取与用户查询最相似的嵌入。一旦我们拥有这些信息,就可以与我们的聊天机器人开始对话,并从文档中获取最相关的信息。
让我们开始通过Vaadin创建一个新的Spring AI项目。
2. 所需依赖项
我们将使用 Spring Initializr 来创建一个包含以下依赖项的新项目:
- Vaadin
- OpenAI
- Tika Document Reader
- PGvector Vector Database
- Docker Compose Support(可选)
为了正确运行,本教程中的应用程序将使用docker来创建一个配置了PGvector扩展的Postgres实例。否则,我们也可以选择自己喜欢的Postgres实例,并手动安装PGvector扩展。
3. 配置应用程序属性
在编写任何业务逻辑之前,我们需要配置应用程序,以便我们可以选择正确的OpenAI API密钥和模型:
spring.ai.openai.api-key=YOUR_OPENAI_API_KEY
spring.ai.openai.chat.options.model=gpt-4o-mini
在这里,我们决定使用 gpt-4o-mini 模型,但我们可以将其更改为OpenAI中任何其他可用模型。
接下来,我们将配置我们的向量存储:
spring.ai.vectorstore.pgvector.initialize-schema=true
spring.ai.vectorstore.pgvector.index-type=HNSW
spring.ai.vectorstore.pgvector.distance-type=COSINE_DISTANCE
spring.ai.vectorstore.pgvector.dimensions=1536
在这里,我们决定使用 HNSW 作为索引类型,并选择 COSINE_DISTANCE 作为距离类型。我们还将维度设置为 1536,因为这是由 OpenAI 生成的嵌入的维度。
接下来,我们配置一个 docker-compose 文件来启动一个带有 PGvector 扩展的 Postgres 实例:
services:
pgvector:
image: 'pgvector/pgvector:pg16'
environment:
- 'POSTGRES_DB=mydatabase'
- 'POSTGRES_PASSWORD=secret'
- 'POSTGRES_USER=myuser'
labels:
- "org.springframework.boot.service-connection=postgres"
ports:
- '5432'
该文件是一个简单的docker-compose文件,它使用pgvector/pgvector:pg16镜像启动一个Postgres实例,并将端口5432暴露给主机。我们选择使用这个镜像是因为它已经安装并配置了pgvector扩展。此外,我们将告诉应用程序在应用程序停止时停止数据库:
spring.docker.compose.stop.command=stop
在添加了对Docker Compose的支持后,我们的应用程序将使用这个配置文件来处理数据库的创建,并注入正确的属性以连接到数据库。如果我们决定使用不同的数据库,我们可以像通常的Spring Data JPA应用程序那样在application.properties文件中配置连接属性:
spring.datasource.url=jdbc:postgresql://localhost:5432/mydatabase
spring.datasource.username=myuser
spring.datasource.password=secret
spring.datasource.driver-class-name=org.postgresql.Driver
4. 创建一个 Vaadin 应用程序
现在我们的配置已经完成,我们将创建一个 Vaadin 应用程序,允许我们上传一个文档并开始与聊天机器人进行对话。
让我们创建我们应用程序的主要入口点:
@SpringBootApplication
public class RagSpringAiApplication implements AppShellConfigurator {
public static void main(String[] args) {
SpringApplication.run(RagSpringAiApplication.class, args);
}
}
我们正在使用 AppShellConfigurator 接口将应用程序 shell 配置为标准的 Vaadin 应用程序。
接下来,我们将创建一个简单的布局以检查一切是否正常:
@Route("")
@PageTitle("Chatbot")
public class MainView extends VerticalLayout {
public MainView() {
add(new H1("Hello, World!"));
}
}
如果一切正常,我们应该会看到一个标题为“Hello, World!”的简单页面:

现在我们已经有了一个简单应用程序的框架,我们可以开始构建所需的所有服务和组件了。
5. 创建上传组件
首先,我们需要一个组件,允许我们将文档上传到服务器。为此,我们将使用 Vaadin 的 Upload 组件,并根据我们的需求进行扩展:
private Upload createUploadComponent() {
MultiFileMemoryBuffer buffer = new MultiFileMemoryBuffer();
Upload upload = new Upload(buffer);
upload.setAcceptedFileTypes(".txt", ".md", ".pdf");
upload.addSucceededListener(handleUpload(buffer));
upload.setWidthFull();
List<String> savedResources = jdbcTemplate.queryForList("SELECT distinct metadata->>'source' FROM vector_store", String.class);
uploadedFiles.setItems(savedResources);
return upload;
}
此方法创建了一个 Upload 组件,只接受 .txt、.md 和 .pdf 文件。我们使用 handleUpload 方法来处理上传,并将组件的宽度设置为全宽。由于我们使用的是 PostgreSQL,因此可以轻松地注入 JdbcTemplate 来查询数据库并获取已上传文件的列表,以便加载先前上传的文件。一旦我们有了已上传文件的列表,我们就可以将它们显示在一个 MultiSelectComboBox 组件中,以便选择我们想要聊天的文件。为了简化,我们不会处理多个用户的上下文。因此,所有加载的文件将对所有用户可用。要处理多个用户,我们可以通过用户 ID 或会话 ID 来过滤文件。
接下来,让我们实现 handleUpload 方法:
private ComponentEventListener<SucceededEvent> handleUpload(MultiFileMemoryBuffer buffer) {
return event -> {
String fileName = event.getFileName();
TikaDocumentReader tikaReader = new TikaDocumentReader(new InputStreamResource(buffer.getInputStream(fileName)));
TextSplitter textSplitter = new TokenTextSplitter();
List<Document> parsedDocuments = textSplitter.apply(tikaReader.get());
parsedDocuments.forEach(document -> document.getMetadata().put("source", fileName));
vectorStore.accept(parsedDocuments);
uploadedFiles.getListDataView().addItem(fileName);
};
}
此方法创建一个 TikaDocumentReader 和一个 TokenTextSplitter 来解析文档并将其分割成块。然后,我们将嵌入存储在数据库中,并将文件名添加到已上传文件的列表中。保存文件名使我们能够查询数据库,以便找到与用户查询最相似的嵌入。
vectorStore 是一个 VectorStore 的实例,我们通过 Spring 的依赖注入来注入它。除非我们想要自定义行为,否则我们可以使用 Spring AI 提供的默认实现。我们可以轻松替换 VectorStore 接口的实现,以使用不同的数据库或存储系统。在后台,VectorStore 将使用 OpenAI 来生成嵌入并将其存储在数据库中。我们可以使用 application.properties 文件配置不同的嵌入生成器和存储系统。
接下来,让我们在主视图中显示上传组件和已上传文件的选择器:
private final transient VectorStore vectorStore;
private final transient JdbcTemplate jdbcTemplate;
private final MultiSelectComboBox<String> uploadedFiles;
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout);
}
如果我们现在运行这个应用程序,我们应该会看到上传组件和已上传文件的列表:

我们现在可以上传文档,并让应用程序处理它。一旦文档处理完毕,我们可以在多选组合框中查看已上传文件的列表。
6. 创建ChatService
现在我们已经上传了文档,我们希望创建一个类似聊天的视图,让我们可以与其进行互动。
在使用图形用户界面之前,我们希望将聊天逻辑从视图中抽象出来,放在一个Spring服务中。 简而言之,我们需要一个方法,该方法接受一个提示、一个会话ID和一个源文件列表,然后返回聊天机器人的响应。
首先,我们将定义一个系统提示,以指导LLM模型如何回应用户查询:
private static final String SYSTEM_PROMPT = """
You are an expert in various domains, capable of providing detailed and accurate information.
Using the context provided by recent conversations, answer the new question in a concise and informative manner.
Limit your answer to a maximum of three sentences.
Your response is always a simple text.
""";
其次,我们将使用由 Spring AI 提供的 ChatMemory 抽象来创建一个内存中的聊天历史记录。这将使我们能够将对话历史保存在内存中,以便为聊天机器人提供历史背景,并在用户返回聊天时加载对话历史。
接下来,我们将为聊天客户端附加一个 QuestionAnswerAdvisor,以便根据源文件对用户查询进行数据库查询,找到最相似的嵌入。
这个顾问将使用 VectorStore 来查询数据库,并获取与用户查询最相似的嵌入:
private final ChatClient chatClient;
private final ChatMemory chatMemory;
public ChatService(ChatClient.Builder chatClientBuilder,
VectorStore vectorStore) {
chatMemory = new InMemoryChatMemory();
QuestionAnswerAdvisor questionAnswerAdvisor = new QuestionAnswerAdvisor(vectorStore);
this.chatClient = chatClientBuilder
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory),
questionAnswerAdvisor,
new SimpleLoggerAdvisor())
.build();
}
此外,为了简化,我们使用 SimpleLoggerAdvisor 将聊天记录记录到控制台中。此外,Spring AI 提供了这种抽象,使我们可以轻松更换顾问并自定义聊天机器人的行为。我们可以将顾问视为一种责任链模式,其中每个顾问可以在将消息发送到 LLM 模型之前对其进行修改——类似于 Spring Security 中的过滤器。在构造函数的末尾,我们将所有部分组装在一起,并拥有一个可以在我们的 ChatService 中使用的 ChatClient 实例。
请记住,我们在这里并没有指定要使用哪个模型。我们知道,我们将 OpenAI 定义为此项目的唯一依赖项,因此 ChatClient 将使用 OpenAI 作为 LLM 模型。如果我们想使用不同的模型,首先需要在 pom.xml 文件中包含该依赖项,然后使用 @Qualifier 注解注入正确的模型。或者,我们可以明确地使用正确的模型构建 ChatClient:
var openAiApi = new OpenAiApi(System.getenv("OPENAI_API_KEY"));
var openAiChatOptions = OpenAiChatOptions.builder()
.withModel("gpt-3.5-turbo")
.withTemperature(0.4)
.withMaxTokens(200)
.build();
var chatModel = new OpenAiChatModel(this.openAiApi, this.openAiChatOptions);
我们不需要担心模型配置,因为我们已经在 application.properties 文件中设置好了。ChatClient 将会使用我们在配置文件中指定的模型。
最后,我们将创建一个方法,该方法接受一个问题、一个对话ID以及一个源文件列表,并返回来自聊天机器人的响应:
public ChatResponse ask(String question, String conversationId, Set<String> sourceFiles) {
String sourcesFilter = String.format("source in ['%s']", String.join("','", sourceFiles));
return chatClient.prompt()
.user(question)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.advisors(spec -> spec.param(FILTER_EXPRESSION, sourcesFilter))
.call()
.chatResponse();
}
首先,我们创建用于通过源文件过滤嵌入的过滤表达式。接着,我们使用用户问题、会话ID和过滤表达式提示ChatClient。最后,我们返回聊天响应。
在构造函数中配置advisors只是工作的一半。正确使用advisors的另一部分是,我们必须在每个提示中传递所需的参数。在这个例子中,我们将对话ID传递给MessageChatMemoryAdvisor,并将过滤表达式传递给QuestionAnswerAdvisor。这些advisors如何使用这些参数取决于advisor的实现。例如,我们使用source元数据字段通过源文件过滤嵌入。在内部,QuestionAnswerAdvisor将在查询VectorStore时使用此信息。这个advisor提供了一种通过源文件过滤嵌入的简单方法。我们可以使用更复杂的过滤器,通过用户ID、会话ID或其他任何元数据字段来过滤嵌入。
7. 创建 ChatView
现在我们有了聊天服务,我们可以创建一个视图,让我们可以与文档进行聊天。
首先,我们将创建一个简单的 TextField 来输入用户提示:
private TextField createMessageField() {
TextField questionField = new TextField("Ask your question");
questionField.setWidthFull();
return questionField;
}
接下来,我们将创建一个Button,让我们可以将消息发送到我们的LLM模型:
private Button createSendButton(ChatService chatService, TextField messageField) {
Button askButton = new Button(VaadinIcon.PAPERPLANE.create(), handleNewMessageRequest(chatService, messageField, chatContainer));
askButton.addThemeVariants(ButtonVariant.LUMO_PRIMARY);
askButton.addClickShortcut(Key.ENTER);
return askButton;
}
我们使用 handleNewMessageRequest 方法来处理用户请求。简而言之,我们读取用户输入,将用户消息添加到聊天容器中,向聊天服务请求响应,并将聊天机器人的响应添加到聊天容器中,该容器是一个 VerticalLayout:
private ComponentEventListener<ClickEvent<Button>> handleNewMessageRequest(ChatService service, TextField messageField, VerticalLayout chatContainer) {
return _ -> {
if (StringUtils.isBlank(messageField.getValue())) {
Notification.show("Please enter a question");
} else {
chatContainer.add(getMessageBlock(new UserMessage(messageField.getValue())));
AssistantMessage answer = service.ask(messageField.getValue(),
UI.getCurrent().getSession().getSession().getId(), uploadedFiles.getValue())
.getResult().getOutput();
chatContainer.add(getMessageBlock(answer));
}
};
}
我们使用会话 ID 作为对话 ID 以简化历史记录管理。为了删除历史记录,我们将创建一个删除按钮,该按钮将从 ChatMemory 实例中移除对话历史记录:
private Button createClearHistoryButton() {
Button clearHistory = new Button(VaadinIcon.TRASH.create(), handleSessionClear());
clearHistory.addThemeVariants(ButtonVariant.LUMO_ERROR);
return clearHistory;
}
现在,我们将在 MainView 中组合所有组件:
public MainView(VectorStore vectorStore,
JdbcTemplate jdbcTemplate,
ChatService chatService) {
this.vectorStore = vectorStore;
this.jdbcTemplate = jdbcTemplate;
this.chatService = chatService;
chatContainer = createChatContainer();
setSizeFull();
TextField messageField = createMessageField();
Button askButton = createSendButton(chatService, messageField);
Button clearHistory = createClearHistoryButton();
HorizontalLayout messageBar = new HorizontalLayout(messageField, askButton, clearHistory);
messageBar.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
messageBar.setWidthFull();
messageBar.setFlexGrow(1, messageField);
Scroller scroller = new Scroller(chatContainer);
scroller.setWidthFull();
VerticalLayout chatBox = new VerticalLayout();
chatBox.setMaxHeight(80, Unit.PERCENTAGE);
chatBox.add(scroller, messageBar);
chatBox.setFlexGrow(1, scroller);
uploadedFiles = new MultiSelectComboBox<>("Files to include");
uploadedFiles.setWidthFull();
Upload upload = createUploadComponent();
HorizontalLayout filesLayout = new HorizontalLayout(upload, uploadedFiles);
filesLayout.setWidthFull();
filesLayout.setDefaultVerticalComponentAlignment(Alignment.BASELINE);
filesLayout.setFlexGrow(1, uploadedFiles);
add(filesLayout, new Hr(), chatBox);
setFlexGrow(1, chatBox);
setWidthFull();
}
如果我们现在运行应用程序,我们应该会看到可以与文档聊天的聊天视图:
8. 测试应用程序
让我们通过上传文档并与聊天机器人对话来测试应用程序。之前,我们上传了一份关于如何安装MongoDB服务器的文档。
首先,让我们询问聊天机器人如何在不指定源文件的情况下备份MongoDB服务器:
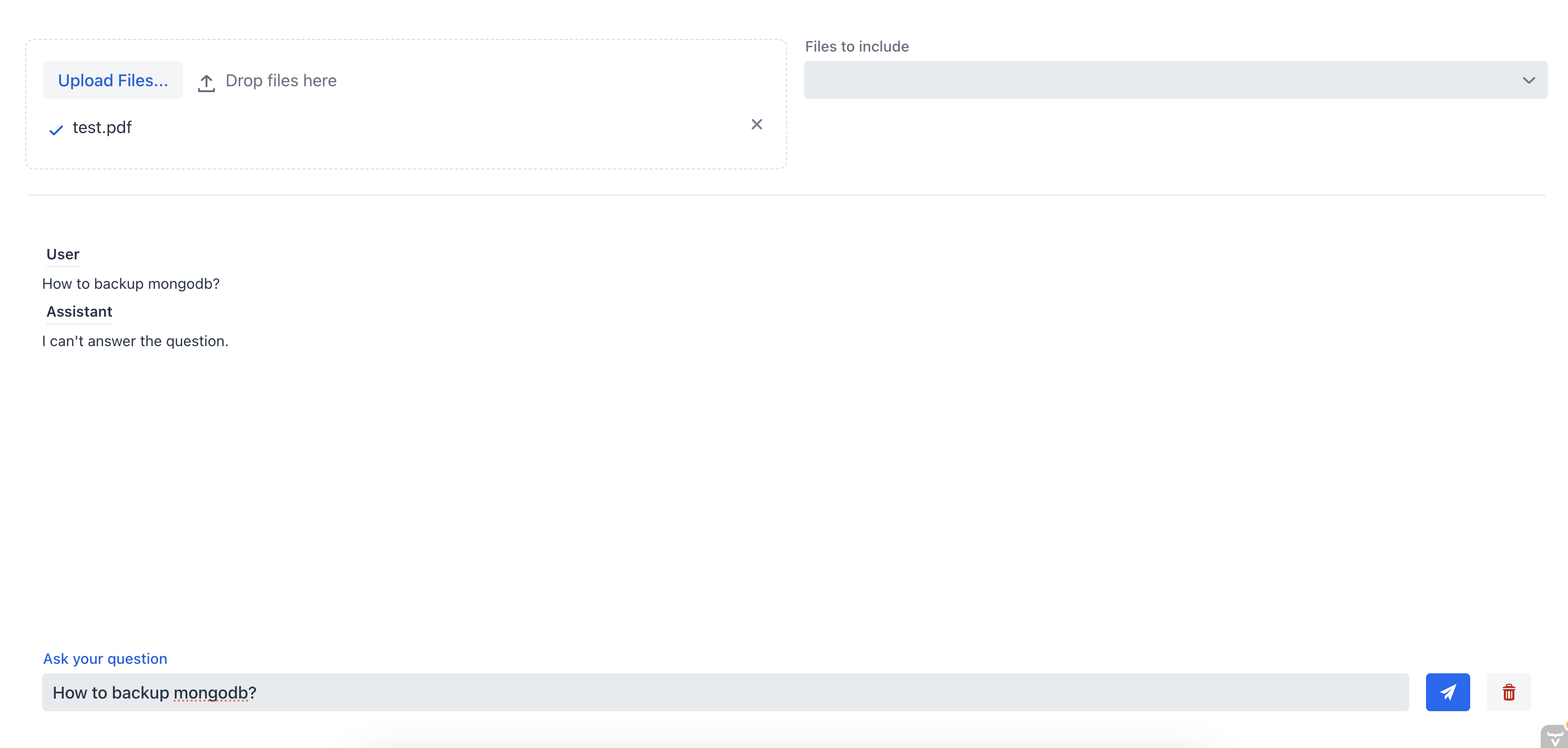
正如我们所见,聊天机器人无法提供一个好的答案,因为它没有文档的上下文。现在,让我们向聊天机器人提出同样的问题,但这次我们将从多选组合框中选择源文件:
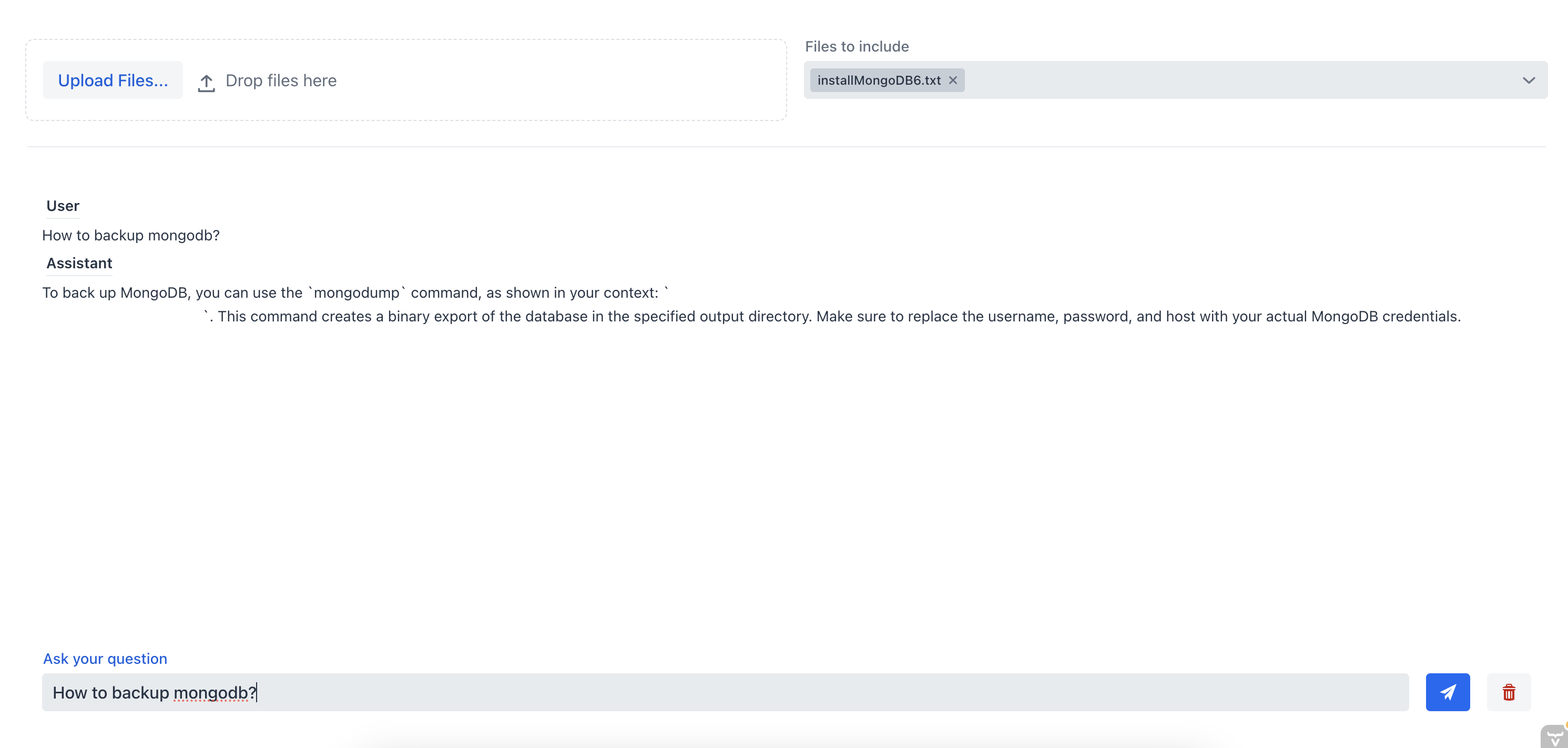
在这个例子中,聊天助手能够提供正确的答案,因为它拥有文档的上下文信息。这展示了RAG聊天机器人的有效性;通过为聊天机器人提供上下文,我们可以从一个或多个文档中获取最相关的信息。
9. 结论
在本教程中,我们学习了如何使用 Spring AI 创建一个完整的 RAG 聊天机器人系统,该系统允许我们与上传的文档进行对话。我们使用 TikaDocumentReader 来解析文档,然后将文档的片段发送到 OpenAI 以创建 embeddings。这些 embeddings 使用 pgvector 存储在 Postgres 数据库中,我们可以查询数据库以获取与用户查询最相似的 embeddings。一旦我们获得了这些信息,就可以与我们的聊天机器人开始对话,并从文档中获取最相关的信息。
我们可以在 Github 上查看完整代码